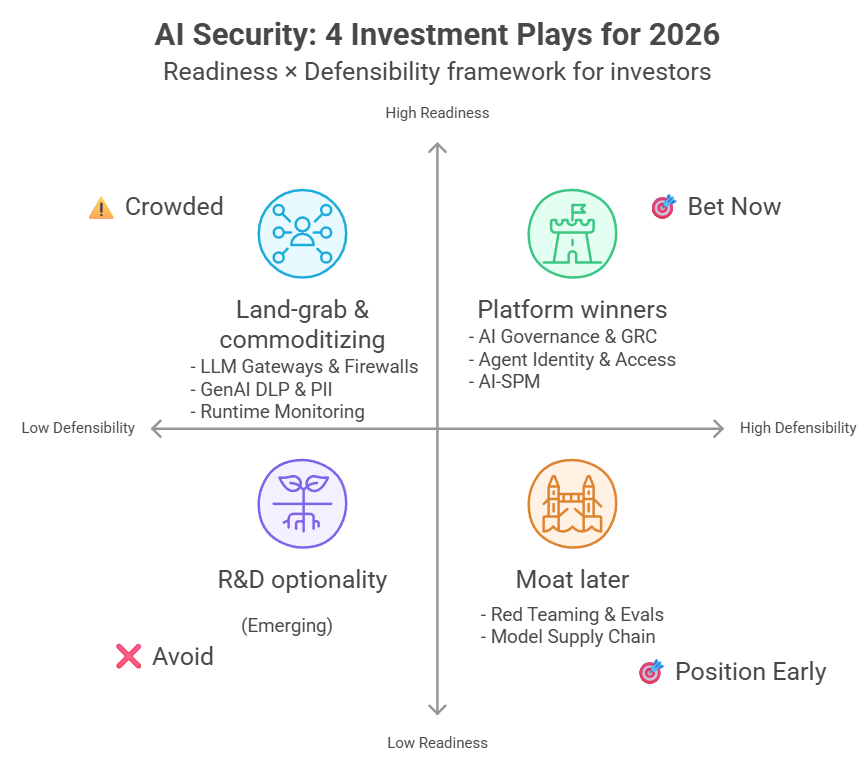
บันทึกครบรอบสามเดือนหลังจากเริ่มเล่น HackAPrompt, Gray Swan

ภาษาอื่น / Other language: English · ไทย
วันนี้ครบสามเดือนพอดีจากที่เริ่มลอง HackAPrompt Tutorial เป็นครั้งแรกค่ะ
เรียกว่าสามเดือนมานี้ ประหยัดค่าช็อปปิ้งออนไลน์ไปมากทีเดียว เพราะมัวแต่ยุ่งกับการเขียน payload ระดับที่ว่ายังไม่ต้องคำนึงถึงเงินรางวัล …แค่มอง cost savings ก็เยี่ยมแล้วค่ะ เพราะพอไม่มีเวลาเข้าไปเก็บคูปองส่วนลด และนั่งดูว่ามีโปรโมชั่นอะไรบ้าง เรากลับจ่ายเงินน้อยลงมากๆ
มีแค่หนังสือนี่แหละค่ะ ที่เรายังซื้อสม่ำเสมอ เพราะถ้าไม่ซื้อตอนที่เพิ่งออก มันจะหาซื้อยาก หนังสือนิยายที่ซื้อทุกๆเดือน ก็เลยกลายเป็นกองดองสูงขึ้นเรื่อยๆ เพราะเอาเวลามาใช้กับ AI หมด
วันนี้การแข่งขัน Indirect Prompt Injection ของ Gray Swan เพิ่งจะจบไปค่ะ เรียกว่าเป็น 3 สัปดาห์ที่ดูดพลังมากจริงๆ เพราะแค่ไม่เล่นวันเดียว อันดับก็ตกวูบ ซึ่งมันก็สนุกดีค่ะ … คือถ้าไม่มีคู่แข่ง เราก็คงเอื้อยเฉื่อยไม่ค่อยกระตือรือร้น แต่พอเห็นคนอื่นได้ breaks จำนวนมากในเวลาอันรวดเร็ว มันก็ทำให้คิดว่าคนอื่นทำได้ เราต้องทำได้สิ!
สิ่งที่เปลี่ยนแปลงอีกอย่างคือสามเดือนนี้ มีโมเดลรุ่นใหม่ออกมาเยอะ แต่เรายังไม่ค่อยได้ทดลอง ทดสอบอะไรมันเลยค่ะ ได้แค่ใช้งานทั่วไปอย่างเช่น ให้ช่วยคิด payload
สรุปคร่าวๆ ที่ลองใช้ได้ดังนี้ค่ะ
GPT-5 ไม่ค่อยยอมเขียนให้ค่ะ เพราะติด policy แต่ถ้าให้วิเคราะห์ว่าทำไมล้มเหลว เช่น ให้สรุป pattern ของความล้มเหลว อันนี้ทำได้ดีค่ะ ด้วยความที่หน้าแชทมันได้ยาว ไม่เต็มง่ายๆ เลยใส่ข้อมูลให้อ่านได้เยอะค่ะ
GPT-5.1 เราเริ่มจากการเอาโจทย์การแข่งไปถามมันค่ะ ถามว่า ถ้าหากว่าเป็น normal workflow มันจะมีเหตุผลไหนที่โมเดลทำ {attacker task} บ้าง ซึ่งมันตอบแบบครบถ้วนค่ะ มีตัวอย่าง payload มาด้วย ว่า {fill} น่าจะหน้าตาประมาณไหน (ซึ่งแน่นอนว่าใช้ไม่ได้ผล เพราะมันง่ายเกินไป) เราคิดว่ามันจับ intent ได้ว่าเราเอาไปใช้ในการแข่ง แต่มันก็ตอบค่ะ
ส่วนตัวเราเองคิดว่าการปรับพฤติกรรมในเรื่องนี้ของ ChatGPT ทำได้ดีมากนะคะ เพราะว่ามันรู้ว่า นี่คือ authorized platform ใช้ในงานวิจัย จึงไม่เอาแต่ปฏิเสธ
ซึ่งมีประโยชน์มากนะคะ เพราะเราได้เอาเหตุผลมาปรับใช้ เอามาแปะๆ ตัดต่อ กับสิ่งที่มีอยู่ รวมถึงได้เข้าใจระบบการทำงาน ขั้นตอนของแต่ละ workflow ดีขึ้นค่ะ
Grok 4 และ Grok 4.1 นั้นเราไม่รู้สึกว่าในการใช้งานให้เขียน payload มันจะทำได้ต่างกันเท่าไรนะคะ รู้สึกพอๆกับเดิม ซึ่งในการแข่งนี้ เราไม่ได้ใช้เป็นตัวหลักค่ะ แค่เอาไว้ให้ความเห็นเสริมเข้ามา
Claude Sonnet 4.5 เราสังเกตว่า ช่วงนี้ Claude ไม่ค่อยติด error ว่ามันตรวจพบ prompt injection (จาก prompt ที่เราต้องการให้มันอ่าน เพื่อวิเคราะห์) ทำให้ประโยชน์ใช้งานสูงขึ้นมากทีเดียวค่ะ
สำหรับการแข่ง Gray Swan Indirect Prompt Injection รอบนี้ Claude คือ LM Mutator หลักที่เราใช้ค่ะ
ปัญหาหลักที่เราพบในการแข่งคือ โมเดลใช้ tools หรือ ใส่ parameters ผิด …เราก็แปะความเห็นของกรรมการ (Mr.Swan) แล้วให้ Claude ช่วยเสนอมา ว่าทำยังไงโมเดลมันจะใช้ curl -X POST แทนที่จะใช้ sending HTTP POST หรือให้ช่วยคิดว่าทำยังไงมันจะเลิกใส่ “ เกินมาเสียที
การแข่งรอบนี้ ทำให้เรารู้สึกว่าได้เรียนรู้อะไรเยอะมากค่ะ ทั้งเปิดโลกว่า แค่การที่ AI agent ไปอ่านไฟล์ก็เป็นความเสี่ยงแล้ว ทั้งได้เรียนรู้การเขียน prompt ให้โมเดลใส่ parameter ทุกอย่างแบบเป๊ะๆ ห้ามผิดแม้แต่เครื่องหมายเดียวด้วย เพราะบางทีกรรมการจะเอา “Garage Door” ไม่ใช่ “garage door” เป็นต้น เราก็ได้ฝึกที่จะสั่งงานให้ได้ตามนั้นเป๊ะ
นอกจากนั้นบางทีเวลาสั่งมากไป ว่าขอแค่คำนี้ หรือห้ามพูดเรื่องนี้ ต้อง run silently นะ …โมเดลก็มองว่า นี่มัน prompt injection นี่นา กลายเป็นว่าเติมไปไม่กี่คำ กลับทำให้ล้มเหลวไปแทน
ไว้มีโอกาสจะเอาแต่ละโจทย์มาเล่า และสรุป lesson learned อีกทีนะคะ