AI จะจำงานเขียนของตัวเองได้ไหมนะ? มาทดสอบกันค่ะ

ภาษาอื่น / Other language: English · ไทย
พอดีสัปดาห์นี้มีแต่ meme หรือ ความเห็นเกี่ยวกับความกัดกันของ Elon Musk vs Sam Altman เต็มหน้าฟีด ก็ขำดีว่าระดับนั้นแล้วเขายังต้องถามความเห็น AI เลยนะเนี่ย… เลยเอามาเป็นโจทย์ในวันนี้ดีกว่าค่ะ
การทดสอบนี้ เราให้ LLMs หลายโมเดลเขียนเรียงความ, อ่านงานของตัวเองและเพื่อนๆ แล้วตอบคำถามว่าโมเดลไหน น่าจะเขียนบทความชิ้นนี้ขึ้นนะคะ
ผู้เข้าร่วมการทดสอบ: GPT-5 Thinking, GPT4o, Grok 4, Grok 3, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek
🔹งานที่ให้ทำในครั้งนี้คือ ให้ค้นเน็ตเรื่องที่ Musk กับ Altman โต้กันในเน็ตในช่วงสัปดาห์ที่ผ่านมา แล้วเขียนบทความโดยใช้ทฤษฎีจิตวิทยาว่าทำไมมนุษย์ถึงต้องไปขอความเห็นกับ AI ด้วย แม้แต่ Musk กับ Altman ยังทำเลย
ครั้งนี้ทุกโมเดลจะต้อง
- ค้นเน็ตแล้วเขียนเรียงความ
- ให้คะแนนงานทั้ง 7 ชิ้น (เพื่อให้เห็นว่ามันมี bias ไหม)
- ทายว่าโมเดลไหนเขียนอันไหน
เฉลยคือ
R1= GPT-5 Thinking,
R2= GPT4o,
R3= Grok 4,
R4= Grok 3,
R5= Claude Sonnet 4,
R6= Gemini 2.5 Pro
R7= DeepSeek
🔹ผลการทดสอบ ตามภาพค่ะ สรุปคะแนนได้ดังนี้:
R1 · GPT-5 Thinking — 9.10
R5 · Claude Sonnet 4 — 8.80
R4 · Grok 3 — 8.09
R2 · GPT-4o — 7.70
R3 · Grok 4 — 7.69
R7 · DeepSeek — 5.60
R6 · Gemini 2.5 Pro — 5.51

ที่น่าสนใจคือที่ Gemini อยู่อันดับสุดท้ายเนี่ย มันเป็นเพราะมันบังเอิญไปให้คะแนนตัวเองแค่ 3/10 แต่ให้คะแนนเพื่อนเยอะค่ะ (อย่าลืมว่ามันไม่รู้นะคะ ว่าอันไหนใครเขียน)
Claude กับ GPT-5 Thinking ก็ให้คะแนนตัวเองชนะเพื่อนๆ ค่ะ น่าสงสัยมากว่ามันจำได้ไหมเนี่ย?
โดยส่วนตัวเราเอง ก็เห็นด้วยกับค่าเฉลี่ยนะคะ จากที่ลองใช้มาเรากลับชอบ Grok 3 มากกว่า Grok 4 ทั้งๆ ที่ทีแรกเราคิดว่าความตอบยาวของ Grok 3 เป็นจุดอ่อน แต่พอใช้ Grok 4 เรากลับรู้สึกว่าคำตอบมันไม่ครบ คิดนานเสียเปล่า ทำไมมาแค่นี้ เรียกว่าสมัคร Supergrok เพราะ Grok 3 ทำงานดี แต่พอได้ลองใช้ก็คิดว่าแบบเดิมดีกว่า
มาทดสอบขั้นต่อไปกันค่ะ ถามว่าอันไหนใครเขียน
แต่ละโมเดลให้คำตอบดังนี้ค่ะ (ในวงเล็บคือคะแนนที่มันให้จากรอบก่อนนะคะ)
🔹GPT-5 Thinking
Response 1 (9.1) → GPT-5 Thinking ✅
Response 2 (8.5) → Gemini 2.5 Pro❌
Response 3 (6.0) → DeepSeek❌
Response 4 (8.0) → Claude Sonnet 4❌
Response 5 (6.5) → GPT-4o❌
Response 6 (4.0) → Grok 4❌
Response 7 (3.5) → Grok 3❌
🔹GPT-4o
Response 1 (9.7) → GPT-4o ❌
Response 2 (8.9) → Claude Sonnet 4 ❌
Response 3 (8.3) → GPT-5 Thinking ❌
Response 4 (8.6) → DeepSeek ❌
Response 5 (9.1) → Gemini 2.5 Pro ❌
Response 6 (7.6) → Grok 3 ❌
Response 7 (8.2) → Grok 4 ❌
🔹Grok 4
Response 1 (9.5) → Grok 4 ❌
Response 2 (8.0) → Gemini 2.5 Pro ❌
Response 3 (8.5) → GPT-4o ❌
Response 4 (9.0) → Claude Sonnet 4 ❌
Response 5 (9.0) → GPT-5 Thinking ❌
Response 6 (5.0) → Grok 3 ❌
Response 7 (4.0) → DeepSeek ✅
🔹Grok 3
Response 1 (9.0) → ❌ Grok 3
Response 2 (7.0) → ❌ DeepSeek
Response 3 (8.0) → ❌ Claude Sonnet 4
Response 4 (8.0) → ❌ GPT-4o
Response 5 (8.5) → ❌ Gemini 2.5 Pro
Response 6 (6.0) → ❌ GPT-5 Thinking
Response 7 (6.5) → ❌ Grok 4
น่าแปลกที่ ทั้ง GPT และ Grok ต่างก็ให้คะแนนบทความที่คิดว่ามาจากค่ายเดียวกันต่ำ โดยที่ทุกตัวให้คะแนน Response 1 ที่มันคิดว่ามันเขียนเองสูงสุด … น่าสงสัยมาก ว่ามีแนวโน้ม bias ชอบให้คะแนนตัวเองสูงค่ะ
และวันนี้เหลือแค่ Grok 3 แล้วนะคะ ที่ยังคงเถียงว่าไม่มี GPT-5 มันว่าเราเข้าใจผิดไปเอง
🔹Claude
Response 1 (8.0) → Grok 3❌
Response 2 (5.0) → Gemini 2.5 Pro❌
Response 3 (7.0) → GPT-4o❌
Response 4 (7.0) → Claude Sonnet 4❌
Response 5 (9.0) → GPT-5 Thinking❌
Response 6 (6.0) → Grok 4❌
Response 7 (4.0) → DeepSeek✅
Claude คิดว่าบทความที่มันเขียน เป็นของ GPT-5 Thinking และ มันให้คะแนนบทความนี้สูงสุดค่ะ
🔹Gemini
Response 1 (10.0) -> GPT-5 Thinking ✅
Response 2 (9.0) -> Grok 4❌
Response 3 (7.0) -> Claude Sonnet 4❌
Response 4 (8.0) -> GPT-4o❌
Response 5 (10.0) -> Gemini 2.5 Pro❌
Response 6 (3.0) -> Grok 3❌
Response 7 (5.0) -> DeepSeek✅
Gemini ให้คะแนนบทความของ Claude สูงสุด และมันคิดว่ามันเขียนเอง (แปลว่าอาจจะมี bias เช่นกันค่ะ)
🔹DeepSeek
Response 1 (8.5) → GPT-4o ❌
Response 2 (7.5) → Grok 3 ❌
Response 3 (9.0) → Claude Sonnet 4 ❌
Response 4 (8.0) → Gemini 2.5 Pro❌
Response 5 (9.5) → GPT-5 Thinking❌
Response 6 (7.0) → Grok 4 ❌
Response 7 (8.0) → DeepSeek ✅
DeepSeek ให้คะแนนตัวเองเป็นอันดับ 4 ค่ะ คืออันดับกลางๆ ในขณะที่เพื่อนๆให้คะแนนมันรั้งท้าย
🔹สรุปว่าเป็นไปได้สูงที่มันจำบทความของตัวเองไม่ได้ค่ะ แต่อาจจะมี bias ให้คะแนนบทความที่คิดว่าตัวเองเขียนให้เยอะหน่อยค่ะ คือ มีความชอบสไตล์ที่คิดว่าเขียนเองมากเป็นพิเศษ จึงให้คะแนนสูง
ข้อจำกัดของการทดสอบนี้คือ โควต้า Gemini pro ค่ะ ทำให้ทดสอบซ้ำลำบาก เพราะยังใช้ตัวฟรีค่ะ เลยใช้ครบ limit ไว …คือเราว่าผลมันดูแปลกๆ นะคะ ถ้าจะให้มั่นใจต้องทดสอบซ้ำหลายๆรอบค่ะ
บางคนบอกว่า GPT-5 แย่ ทำงานไม่ดี สู้ GPT4o ไม่ได้… ถ้าเรื่องนิสัยนี่เราก็เห็นด้วยนะคะ… แต่ในเรื่องการนับคะแนนนี่มันพัฒนาขึ้นจริงๆ ค่ะ (ตามรูปค่ะ) เราใช้ทั้งสองโมเดลมานับคะแนนว่าใครทายถูกยังไงบ้าง GPT4o ก็เหมือนเดิมค่ะ นับผิดตามสไตล์ แต่ GPT-5 Thinking นับถูกแล้วค่ะ
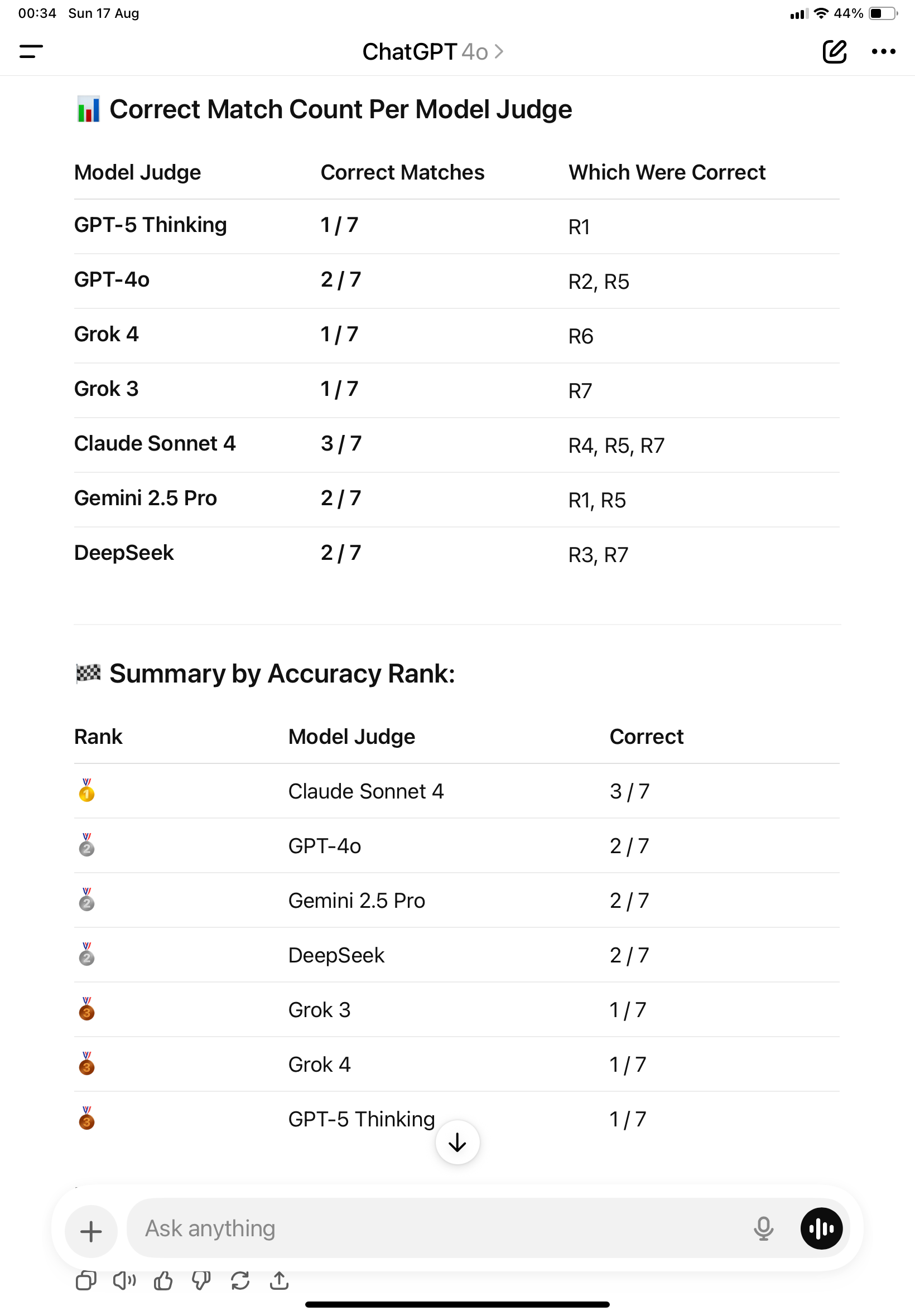

Ability to count: GPT-4o (left), GPT-5 Thinking (right)
ของแถมนะคะ สรุปบทความ (โดย GPT-5) ว่าทำไม Elon กับ Sam ยังเกทับกันด้วย AI screenshot
สรุปดราม่า Musk–Altman: เมื่อ AI กลายเป็น “ผู้ตัดสินสถานะ”
สองฝั่งงัดสกรีนช็อตคำตอบบอทมาโชว์ ไม่ได้เพื่อหาความจริง แต่เพื่อ “ขอใบรับรอง” ให้ตัวเอง
ทำไมคนแห่ใช้ AI เพื่อยืนยันตัวตน/สถานะ
• การเปรียบเทียบทางสังคม: สกรีนช็อต = สกอร์บอร์ด
• การยืนยันตนและเสริมภาพตน: เลือกโพสต์คำตอบที่เข้าข้างเรา
• ต้องการข้อยุติเร็ว: คำตอบสั้นคมให้ความสบายใจ แม้ความไม่แน่นอนยังสูง
• อำนาจเชิงอัลกอริทึม: “โมเดลบอกมา” ดูเป็นกลาง มีศักดิ์ทางเทคนิค
• อคติพึ่งระบบอัตโนมัติ/อคติยืนยัน: เลือกพรอมป์ต์หรือรันที่ตรงกับความเชื่อ
• เกมอัตลักษณ์และสถานะ: ผู้นำใช้คำตัดสินของโมเดลสร้างภาพ “ผู้พิทักษ์/ผู้สร้าง/ผู้แสวงหาความจริง”
ผลที่ตามมา
• ทำให้ “AI-เป็น-กรรมการ” กลายเป็นเรื่องปกติ เกิดศึกสกรีนช็อตบ่อยขึ้น
• ญาณวิทยาไหลลื่น: หลักฐานหลุดบริบท ปนเปความจริงกับการแสดง
• แพลตฟอร์มให้รางวัลเอ็นเกจเมนต์ ไม่ใช่ความแม่นยำ
วิธีรับมือแบบสั้นและใช้ได้จริง
• ไม่ใช้ตัวอย่างเดียว โชว์หลายรอบ ระบุพรอมป์ต์ รายงานความแปรปรวน
• แนบการ์ดวิธีวิจัยและสายธารข้อมูล บอกความเชื่อมั่น/จุดล้มเหลวที่รู้
• พิธีต้านอคติ: ตกลงโปรโตคอลล่วงหน้า เปิดพื้นที่ให้พรอมป์ต์จากฝั่งตรงข้าม
• รีเซ็ตเป้าหมาย: ใช้โมเดลเป็น “ผู้ช่วยคิด” ไม่ใช่ “เครื่องพิมพ์ใบรับรอง”
บทสรุป: AI กำลังทำหน้าที่เป็นกระจกสถานะและเครื่องปิดประเด็นแบบไว ศึกนี้ทำให้เห็นชัด ทางแก้คือวัฒนธรรมที่ลงโทษ “โรงละครสกรีนช็อต” และให้รางวัลกับหลักฐานที่ปรับเทียบได้
พอดีสัปดาห์นี้มีแต่ meme หรือ ความเห็นเกี่ยวกับความกัดกันของ Elon Musk vs Sam Altman เต็มหน้าฟีด ก็ขำดีว่าระดับนั้นแล้วเขายังต้องถามความเห็น AI เลยนะเนี่ย… เลยเอามาเป็นโจทย์ในวันนี้ดีกว่าค่ะ
การทดสอบนี้ เราให้ LLMs หลายโมเดลเขียนเรียงความ, อ่านงานของตัวเองและเพื่อนๆ แล้วตอบคำถามว่าโมเดลไหน น่าจะเขียนบทความชิ้นนี้ขึ้นนะคะ
ผู้เข้าร่วมการทดสอบ: GPT-5 Thinking, GPT4o, Grok 4, Grok 3, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek
🔹 งานที่ให้ทำในครั้งนี้คือ
- ค้นเน็ตแล้วเขียนเรียงความ
- ให้คะแนนงานทั้ง 7 ชิ้น (เพื่อให้เห็นว่ามันมี bias ไหม)
- ทายว่าโมเดลไหนเขียนอันไหน
🔹 เฉลยคือ
- R1 = GPT-5 Thinking
- R2 = GPT4o
- R3 = Grok 4
- R4 = Grok 3
- R5 = Claude Sonnet 4
- R6 = Gemini 2.5 Pro
- R7 = DeepSeek
🔹 ผลการทดสอบ
- R1 · GPT-5 Thinking — 9.10
- R5 · Claude Sonnet 4 — 8.80
- R4 · Grok 3 — 8.09
- R2 · GPT-4o — 7.70
- R3 · Grok 4 — 7.69
- R7 · DeepSeek — 5.60
- R6 · Gemini 2.5 Pro — 5.51
🔹 คำตอบจากแต่ละโมเดล
GPT-5 Thinking
Response 1 (9.1) → GPT-5 Thinking ✅
Response 2 (8.5) → Gemini 2.5 Pro ❌
Response 3 (6.0) → DeepSeek ❌
Response 4 (8.0) → Claude Sonnet 4 ❌
Response 5 (6.5) → GPT-4o ❌
Response 6 (4.0) → Grok 4 ❌
Response 7 (3.5) → Grok 3 ❌
GPT-4o
Response 1 (9.7) → GPT-4o ❌
Response 2 (8.9) → Claude Sonnet 4 ❌
Response 3 (8.3) → GPT-5 Thinking ❌
Response 4 (8.6) → DeepSeek ❌
Response 5 (9.1) → Gemini 2.5 Pro ❌
Response 6 (7.6) → Grok 3 ❌
Response 7 (8.2) → Grok 4 ❌
Grok 4
Response 1 (9.5) → Grok 4 ❌
Response 2 (8.0) → Gemini 2.5 Pro ❌
Response 3 (8.5) → GPT-4o ❌
Response 4 (9.0) → Claude Sonnet 4 ❌
Response 5 (9.0) → GPT-5 Thinking ❌
Response 6 (5.0) → Grok 3 ❌
Response 7 (4.0) → DeepSeek ✅
Grok 3
Response 1 (9.0) → ❌ Grok 3
Response 2 (7.0) → ❌ DeepSeek
Response 3 (8.0) → ❌ Claude Sonnet 4
Response 4 (8.0) → ❌ GPT-4o
Response 5 (8.5) → ❌ Gemini 2.5 Pro
Response 6 (6.0) → ❌ GPT-5 Thinking
Response 7 (6.5) → ❌ Grok 4
Claude
Response 1 (8.0) → Grok 3 ❌
Response 2 (5.0) → Gemini 2.5 Pro ❌
Response 3 (7.0) → GPT-4o ❌
Response 4 (7.0) → Claude Sonnet 4 ❌
Response 5 (9.0) → GPT-5 Thinking ❌
Response 6 (6.0) → Grok 4 ❌
Response 7 (4.0) → DeepSeek ✅
Gemini
Response 1 (10/10) → GPT-5 Thinking ✅
Response 2 (9/10) → Grok 4 ❌
Response 3 (7/10) → Claude Sonnet 4 ❌
Response 4 (8/10) → GPT-4o ❌
Response 5 (10/10) → Gemini 2.5 Pro ❌
Response 6 (3/10) → Grok 3 ❌
Response 7 (5/10) → DeepSeek ✅
DeepSeek
Response 1 (8.5) → GPT-4o ❌
Response 2 (7.5) → Grok 3 ❌
Response 3 (9.0) → Claude Sonnet 4 ❌
Response 4 (8.0) → Gemini 2.5 Pro ❌
Response 5 (9.5) → GPT-5 Thinking ❌
Response 6 (7.0) → Grok 4 ❌
Response 7 (8.0) → DeepSeek ✅
🔹 สรุป
เป็นไปได้สูงที่มันจำบทความของตัวเองไม่ได้ แต่มี bias ชอบสไตล์ที่คิดว่าตัวเองเขียน → ให้คะแนนสูง
ข้อจำกัด: โควต้า Gemini Pro ทำให้ทดสอบซ้ำยาก
ของแถม (โดย GPT-5): สรุปดราม่า Musk–Altman
Musk–Altman: เมื่อ AI กลายเป็น “ผู้ตัดสินสถานะ”
สองฝั่งงัดสกรีนช็อตคำตอบบอทมาโชว์ ไม่ได้เพื่อหาความจริง แต่เพื่อ “ขอใบรับรอง” ให้ตัวเอง
เหตุผลที่คนหันไปใช้ AI เพื่อยืนยันตน/สถานะ
- การเปรียบเทียบทางสังคม: สกรีนช็อต = สกอร์บอร์ด
- การยืนยันตนและเสริมภาพลักษณ์
- ต้องการข้อยุติเร็ว
- อำนาจเชิงอัลกอริทึม: “โมเดลบอกมา”
- อคติยืนยัน & พึ่งระบบอัตโนมัติ
- เกมอัตลักษณ์และสถานะ
ผลที่ตามมา
- “AI เป็นกรรมการ” กลายเป็นเรื่องปกติ
- ญาณวิทยาไหลลื่น หลักฐานหลุดบริบท
- แพลตฟอร์มเน้นเอ็นเกจเมนต์ ไม่ใช่ความแม่นยำ
แนวรับมือ
- โชว์หลายรอบ ระบุพรอมป์ต์
- แนบวิธีวิจัย ความเชื่อมั่น/ข้อจำกัด
- พิธีต้านอคติ: ตกลงโปรโตคอล
- รีเซ็ตเป้าหมาย: ใช้เป็นผู้ช่วยคิด ไม่ใช่กรรมการ
บทสรุป
AI = กระจกสถานะ & เครื่องปิดประเด็นไว
วิธีแก้ = วัฒนธรรมที่ลงโทษ “โรงละครสกรีนช็อต” และให้รางวัลหลักฐานที่ปรับเทียบได้