เปิดแผนที่ตลาด AI Security ปี 2026: ใครกำลังชนะ ใครกำลังถูกกลืน และช่องว่างที่ยังเปิดอยู่
ภาษาอื่น / Other language: English · ไทย
บทวิเคราะห์ตลาด AI Security ต้นปี 2026 ผ่านกรอบคิดแบบนักลงทุน: ตลาดกำลังไปทางไหน หมวดไหนกำลังชนะ อะไรจะถูกทำให้เป็นของแถม และถ้าต้องวางเดิมพันวันนี้ จะวางตรงไหน?
AI Security คืออะไร? ทำไมองค์กรถึงต้องซื้อเครื่องมือหลายตัว ไม่ใช่แค่ตัวเดียว
ก่อนจะลงรายละเอียด ลองตั้งภาพรวมให้ตรงกันก่อน
เมื่อองค์กรเริ่มนำ AI หรือ LLM (Large Language Model เช่น ChatGPT, Claude, Gemini) ไปใช้ในงานจริง ไม่ว่าจะเป็น chatbot ตอบลูกค้า ระบบสรุปเอกสาร copilot ช่วยเขียนโค้ด หรือ AI agent ที่ทำงานอัตโนมัติ “ความเสี่ยงแบบใหม่” จะตามเข้ามาทันที
และความเสี่ยงแบบใหม่จำนวนหนึ่งเป็นคนละชนิดกับความเสี่ยงที่ระบบรักษาความปลอดภัยแบบเดิมถูกออกแบบมาเพื่อรับมือ
ตัวอย่างที่พบบ่อย เช่น พนักงานเผลอใส่ข้อมูลลับลงในแชต, ผู้โจมตีฝังคำสั่งอันตรายไว้ในเอกสารหรือข้อมูลที่โมเดลดึงมาอ่าน (indirect prompt injection), ไฟล์โมเดลจากแหล่ง open source มี backdoor/โค้ดอันตรายติดมา (เช่นจากช่องโหว่ของไฟล์ serialization), หรือ AI agent ที่มีสิทธิ์เข้าถึงระบบสำคัญถูกชักจูงให้ทำ “การกระทำที่ไม่ควรถูกอนุญาต” โดยไม่ตั้งใจ
AI Security จึงหมายถึง “ชุดเครื่องมือและบริการ” ที่ออกแบบมาเพื่อจัดการความเสี่ยงเหล่านี้โดยเฉพาะ
ประเด็นสำคัญคือ: AI Security ไม่ใช่ซอฟต์แวร์ชิ้นเดียวที่ซื้อมาแล้วจบ แต่เป็น ชุดควบคุมแบบหลายเลเยอร์ (layered controls) ที่ดูแลการใช้งาน AI ในองค์กร ซึ่งคล้ายระบบรักษาความปลอดภัยของอาคารสำนักงานที่ไม่ได้พึ่งสิ่งใดสิ่งหนึ่ง แต่ประกอบด้วยหลายกลไก ตั้งแต่ประตูคีย์การ์ด กล้องวงจรปิด ระบบตรวจจับควันไฟ เจ้าหน้าที่รักษาความปลอดภัย ไปจนถึงกฎระเบียบและการตรวจสอบมาตรฐานวัสดุ (และในความเป็นจริง เครื่องมือบางตัวอาจทำหน้าที่ได้มากกว่าหนึ่งเลเยอร์)
เพื่อให้คิดง่าย เราแบ่งเลเยอร์หลัก ๆ ได้ดังนี้:
เลเยอร์ก่อนขึ้น production (pre-deployment assurance): ทดสอบก่อนใช้งานจริง ทั้งในมุมความปลอดภัยและคุณภาพ รวมถึงการตรวจสอบไฟล์/ตัวโมเดลจากแหล่งภายนอกก่อนนำมา deploy
เลเยอร์ควบคุมแบบเรียลไทม์ (runtime enforcement) : บังคับใช้นโยบายตรงจุดที่แอปเรียกใช้โมเดล เช่น บล็อก/คัดกรอง prompt ที่เสี่ยง คัดกรองข้อมูลส่วนบุคคล หรือกำหนดสิทธิ์ของ AI agent
เลเยอร์การมองเห็นและการค้นหา (visibility): ทำให้องค์กรเห็นว่าใช้งาน AI อยู่ตรงไหน ใช้กับข้อมูลอะไร ตั้งค่าอะไรผิด และมีจุดเสี่ยงอะไรบ้าง
เลเยอร์หลักฐานและความพร้อมตรวจสอบ (evidence & auditability) : จัดการนโยบาย บันทึกการอนุมัติ สร้างหลักฐานให้ “ตรวจสอบได้จริง” เมื่อมี audit หรือ compliance review
ดังนั้น เกมการแข่งขันในตลาดนี้ไม่ใช่แค่ “ใครตรวจจับเก่งกว่า” แต่เป็น “ใครสร้างจุดควบคุมที่องค์กรต้องใช้ทุกวันได้มากกว่า”
โดยรวมศูนย์ workflow + ข้อมูล + นโยบาย + ช่องทางการเข้าถึงลูกค้า (distribution) ไว้ในที่เดียว
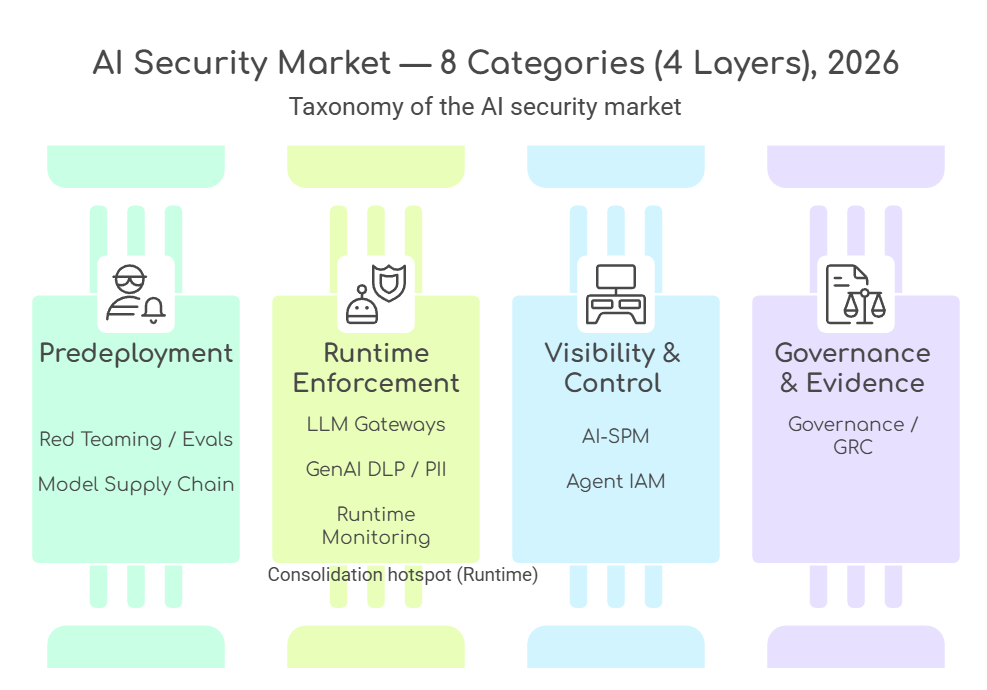
แปดหมวดหมู่ที่ต้องรู้จัก
ภาพแบบ “เลเยอร์” คือโครงใหญ่ ส่วนการวิเคราะห์ตลาดจะจำแนกเป็น 8 หมวดโซลูชันที่พบในตลาดจริง (และบางหมวดอาจอยู่ในเลเยอร์เดียวกันได้)
เพื่อวิเคราะห์ภาพรวมของตลาด เราแบ่งได้เป็น 8 หมวดหลัก โดยเมื่อมองรวมกันจะเห็นว่าเป็นการจัดวาง security stack แบบเดิมใหม่ให้เข้ากับยุค GenAI
- AI Red Teaming & Evals: จำลองการโจมตีและประเมินผลก่อนขึ้น production
- Model Supply Chain Security: ตรวจสอบแหล่งที่มาและความสมบูรณ์ของโมเดล รวมถึงไฟล์และส่วนประกอบที่เกี่ยวข้อง ก่อนนำไปใช้
- LLM Firewalls / Gateways: ด่านหน้าที่บังคับใช้กฎความปลอดภัยกับ prompt และ response เช่น บล็อกคำสั่งเสี่ยงและปิดทับข้อมูลอ่อนไหว
- GenAI DLP (Data Loss Prevention) & PII Redaction: กันข้อมูลอ่อนไหวและ PII รั่วไหลผ่านช่องทาง AI
- AI Runtime Monitoring: ติดตามพฤติกรรมโมเดลแบบเรียลไทม์ระหว่างใช้งานจริง
- AI-SPM (AI Security Posture Management): สำรวจการใช้งาน AI ที่อยู่นอกการกำกับดูแล (shadow AI) และตรวจหาการตั้งค่าที่เสี่ยงหรือผิดพลาดในองค์กร
- Agent Identity & Access: จัดการตัวตนและสิทธิ์ของ AI agent เพื่อกำหนดว่า “ใครทำอะไรได้แค่ไหน” และตรวจสอบย้อนหลังได้
- AI Governance & GRC (Governance, Risk, Compliance): ระบบกำกับดูแลความเสี่ยงและ compliance (นโยบาย, approval, หลักฐานสำหรับ audit)
ก่อนจะสรุปภาพรวม เรามาดูเกมจริงในแต่ละหมวดกันก่อน
เจาะแต่ละหมวด: เกมจริงเป็นอย่างไร
1) AI Red Teaming: เครื่องมือเริ่มเป็นของพื้นฐาน แต่ความเชี่ยวชาญยังมีราคา
หมวดนี้คือการทดสอบเชิงรุกเพื่อหาช่องโหว่ล่วงหน้า โดยจำลองพฤติกรรมผู้โจมตีและทดสอบเคสเสี่ยงก่อนขึ้น production จุดที่น่าสนใจคือวันนี้ “เครื่องมือทดสอบพื้นฐาน” กลายเป็นของที่เข้าถึงได้ง่ายมาก เพราะมี open source ให้ใช้หลายตัว เช่น Garak ของ NVIDIA, Promptfoo และ Inspect ของ UK AI Security Institute เลยทำให้ test harness เริ่มเป็นของพื้นฐานที่ทีมเอาไปต่อยอดได้เอง
แต่สิ่งที่ยังเป็นตัวทำเงินจริงมักไม่ใช่ตัวเครื่องมืออย่างเดียว แต่อยู่ที่ (1) ความสามารถในการออกแบบชุดทดสอบและสถานการณ์โจมตีที่ซับซ้อน (2) ความครอบคลุมของเคสยาก เช่น indirect prompt injection, agentic scenarios, memory poisoning และ (3) บริการที่ช่วยองค์กรทดสอบต่อเนื่องแบบเป็นรอบ ไม่ใช่ทำครั้งเดียวแล้วจบ
ถ้าจะยกตัวอย่างเชิงทรัพย์สินทางปัญญา Adversa AI มีสิทธิบัตร US11275841B2 ที่อธิบายแนวคิดการประเมินช่องโหว่ของแอป AI โดยทดสอบการใช้ “ชุดมาตรการป้องกันหลายตัวร่วมกัน” กับการโจมตีอย่างน้อย 2 รูปแบบที่ต่างกันในเชิง threat type (ไม่ใช่แค่เปลี่ยนข้อความ prompt เล็กน้อย) และใช้ชุดข้อมูลอย่างน้อย 1 ชุด จากนั้นจึงปรับระบบให้เลือกชุดป้องกันที่มีประสิทธิภาพเชิงคอมพิวต์มากขึ้น เช่นลดภาระทรัพยากรหรือเวลาในการรัน
2) Model Supply Chain: ยังไม่ถูกทำให้เป็นมาตรฐาน แต่เลี่ยงยากขึ้นเรื่อย ๆ
หมวดนี้คือการ “เช็กโมเดลก่อนเอาไปใช้จริง” โดยตรวจไฟล์โมเดลและไฟล์ประกอบ เพื่อดูว่ามีสิ่งแปลกปลอมหรือช่องทางที่ทำให้ระบบถูกควบคุมได้หรือไม่ เช่นโค้ดอันตรายหรือ backdoor ที่ซ่อนอยู่
อีกจุดที่ต้องระวังคือไฟล์บางชนิดอาจทำให้เกิดการรันโค้ดตอนถูกโหลดเข้าโปรแกรม (unsafe deserialization) และต้องตรวจความน่าเชื่อถือของแหล่งที่มาและความครบถ้วนของไฟล์ (integrity/provenance) ด้วย
ตัวอย่างเช่น HiddenLayer ที่ชูแนวคิด AIBOM เพื่อทำบัญชีส่วนประกอบของโมเดลและตรวจสอบย้อนกลับ (traceability) พร้อมรองรับฟอร์แมตโมเดลหลักหลายแบบตามเอกสารผลิตภัณฑ์
AIBOM คืออะไร
AIBOM (AI Bill of Materials) คือ “รายการส่วนประกอบของโมเดล AI” คล้าย SBOM ในโลกซอฟต์แวร์
ใช้เพื่อทำ inventory และตรวจสอบย้อนกลับว่าโมเดลนี้มีไฟล์/ส่วนประกอบอะไรบ้าง มาจากไหน และผ่านอะไรมา
Protect AI มีทั้งผลิตภัณฑ์ฝั่งองค์กรอย่าง Guardian และเครื่องมือโอเพ่นซอร์สอย่าง ModelScan ส่วนหลังจากถูก Palo Alto Networks เข้าซื้อกิจการ ผลงานของ Protect AI ก็เริ่มถูกนำไปผูกเข้ากับแพลตฟอร์มความปลอดภัยของ Palo Alto มากขึ้น
อีกตัวอย่างคือ JFrog ที่ Hugging Face ระบุว่าร่วมกับเพื่อเพิ่มการสแกนโมเดลบน Hugging Face Hub และแสดงผลการสแกนบนหน้าโมเดลโดยตรง
ส่วนฝั่ง Bosch AIShield มี AISpectra ซึ่งเป็นเครื่องมือสแกนและค้นหา AI assets เพื่อประเมินความเสี่ยง และมี Watchtower เป็นเครื่องมือโอเพ่นซอร์สสำหรับสแกนทั้งไฟล์โมเดลและไฟล์โน้ตบุ๊กที่ใช้พัฒนาโมเดล (เช่น Jupyter Notebook) ในบริบท AI/ML supply chain
นอกจากนี้ AIShield ยังระบุว่าถูกจัดอยู่ในกลุ่ม Representative Vendor ใน Gartner Market Guide ปี 2025 ด้าน AI TRiSM (AI Trust, Risk and Security Management หรือการบริหารความน่าเชื่อถือ ความเสี่ยง และความปลอดภัยของ AI)
จุดที่ทำให้หมวดนี้ “ความเสี่ยงกับโอกาสไม่สมดุล” คือ ถ้าเกิดเหตุใหญ่ที่โยงกับโมเดลใน production เมื่อไหร่ องค์กรจำนวนมากจะเร่งนำเครื่องมือกลุ่มนี้มาใช้แบบก้าวกระโดด ขณะเดียวกันก็เริ่มมีความพยายามผลักมาตรฐานเรื่องการเซ็นและการตรวจสอบที่มาของโมเดล เช่น OpenSSF Model Signing และแนวทางที่อิง Sigstore
3) LLM Firewalls: จากหมวดดาวรุ่งสู่หมวดที่กำลัง commoditize และถูก bundle
หมวดนี้คือ “ด่านหน้า” ของการใช้ LLM ในองค์กร มักอยู่ในรูป gateway/proxy หรือ SDK/API hook ที่คั่นกลางระหว่างแอปกับโมเดล ทำหน้าที่ตรวจ prompt ที่ส่งเข้าและตรวจ response ที่ส่งกลับแบบเรียลไทม์ แล้วบล็อกหรือปิดบังบางส่วนเมื่อเจอความเสี่ยง เช่น ความพยายาม jailbreak, เนื้อหาที่ผิด policy, หรือข้อมูลอ่อนไหวที่ไม่ควรหลุดออกไป
นี่เป็นหนึ่งในหมวดที่ผู้เล่นหนาแน่นและการแข่งขันสูง ทั้งฝั่งสตาร์ทอัพ AI-native ที่ขาย inference protection/guardrails และฝั่งแพลตฟอร์ม security รายใหญ่ที่ฝัง control เหล่านี้เข้าไปในของเดิม อีกด้านก็มีเครื่องมือ open source ให้เอาไปต่อยอดได้ ทำให้ “ของพื้นฐาน” เริ่มถูกกดราคา
ดีล M&A ช่วงปี 2024 ถึง 2025 หลายดีลก็อยู่ในกลุ่มด่านหน้า หรืออยู่ในสาย runtime/lifecycle security ที่วางตัวใกล้ inference perimeter สะท้อนว่าในบางเคส “ซื้อเอา” อาจเร็วกว่า “สร้างเอง” เมื่ออยากลงตลาดให้ทัน
จุดที่แข่งกันจริงมักไม่ใช่แค่ “มีหรือไม่มี” แต่เป็นเรื่องคุณภาพที่พิสูจน์ได้ เช่น latency ที่ไม่ทำให้ระบบช้า ความแม่นของ detection ที่ไม่ทำให้ false positive พุ่ง และความลื่นของการ integrate เข้ากับ stack เดิมขององค์กร
โจทย์นี้ยังยากใน production และยังมีช่องให้หลุดได้ คือการรับมือ prompt injection แบบที่ไม่ได้ส่งคำสั่งอันตรายตรง ๆ แต่ซ่อนอยู่ในเอกสาร ข้อมูลจาก RAG หรือ output จาก tool ซึ่งต้องออกแบบระบบให้ “ลดผลกระทบ” มากกว่าหวังว่าจะบล็อกได้หมด
4) GenAI DLP (Data Loss Prevention) & PII Redaction: เรื่องเก่าในบริบทใหม่
การป้องกันข้อมูลรั่วไหลไม่ใช่เรื่องใหม่ แต่พอ AI กลายเป็น “ช่องทางใหม่” เช่นการพิมพ์ “คำสั่ง/คำถาม” (prompt) เข้าเครื่องมือ GenAI หรือการให้ Copilot (ผู้ช่วย AI ใน Microsoft 365) เข้าถึงคอนเทนต์ในระบบงาน ก็ทำให้ DLP ต้องขยายขอบเขตมาคุมการใช้งาน AI โดยตรง ไม่ใช่คุมแค่อีเมลหรือไฟล์แบบเดิม
ข้อได้เปรียบของผู้เล่นรายใหญ่คือมี policy และ ป้ายกำกับความลับของข้อมูล (sensitivity labels) อยู่แล้ว จึงต่อการบังคับใช้นโยบายเข้ากับ workflow เดิมขององค์กรได้เร็ว ตัวอย่างเช่น Microsoft Purview DLP สามารถกำหนดเงื่อนไขเพื่อจำกัดการใช้ข้อมูลอ่อนไหวใน Copilot ได้ทั้งระดับ prompt และระดับไฟล์/อีเมลที่ติด label
ส่วนสตาร์ทอัพที่มีโอกาส “สร้างมูลค่าเพิ่ม” มักต้องมีจุดต่างที่ชัด เช่นความสามารถด้านหลายภาษา (Private AI ระบุว่ารองรับประมาณ 50 ภาษา และทยอยเพิ่มภาษาใหม่) หรือแนวทาง data privacy vault (คลังเก็บข้อมูลอ่อนไหวแบบแยกส่วน) และ tokenization (ใช้โทเคนแทนข้อมูลจริง) เช่น Skyflow ที่ช่วยจำกัดการกระจายข้อมูลอ่อนไหวโดยไม่ต้องพึ่งการสแกน inline เพียงอย่างเดียว
อีกด้านหนึ่งมีเครื่องมือ open source ให้ต่อยอด เช่น Microsoft Presidio สำหรับตรวจจับและทำ anonymization ของ PII ซึ่งยิ่งเพิ่มแรงกดดันด้านราคาในฟังก์ชันพื้นฐานของหมวดนี้
5) AI Runtime Monitoring: เริ่มจาก observability แต่ปลายทางคือ security
หมวดนี้คือการตามดูพฤติกรรมของระบบ LLM ตอนรันงานจริง เช่น ติดตาม latency และ error, ดู token usage เพื่อประมาณ cost ต่อ request, เก็บ trace/log ให้ไล่สาเหตุได้ และทำ quality checks หรือ eval บางรูปแบบเพื่อเฝ้าระวังปัญหาอย่าง drift และสัญญาณคุณภาพที่สัมพันธ์กับ hallucination
ภาพรวมหมวดนี้มีตัวเลือก open source ที่ใช้งานจริงได้เยอะ เช่น Phoenix, Langfuse และ Helicone ที่ทีมสามารถ self-host และต่อยอดได้ ขณะเดียวกันแพลตฟอร์ม observability รายใหญ่ก็ออก capability เฉพาะสำหรับ LLM แล้ว เช่น Datadog LLM Observability และแนวทาง Observability for AI ของ Splunk
คำถามเชิงการแข่งขันคือ ถ้าสิ่งที่องค์กรต้องการมีแค่ trace กับ log จริง ๆ ผู้เล่น AI-native จะสู้แพลตฟอร์มเดิมที่ลูกค้ามีอยู่แล้วได้อย่างไร
ความต่างที่พอสร้างแรงดึงดูดได้มักอยู่ที่การทำ eval ให้เป็นระบบ และผูกมันเข้ากับการปล่อยของ เช่นมี regression history, evaluation set เฉพาะองค์กร และมี quality gates ใน CI/CD หรือ release workflow เพื่อให้ “ไม่ผ่านก็ไม่ปล่อย” จน observability ขยับไปเป็น security control ได้จริง ไม่ใช่แค่เครื่องมือดูย้อนหลัง
6) AI-SPM (AI Security Posture Management): โตเร็ว แต่มีโอกาสถูกทำเป็นฟีเจอร์
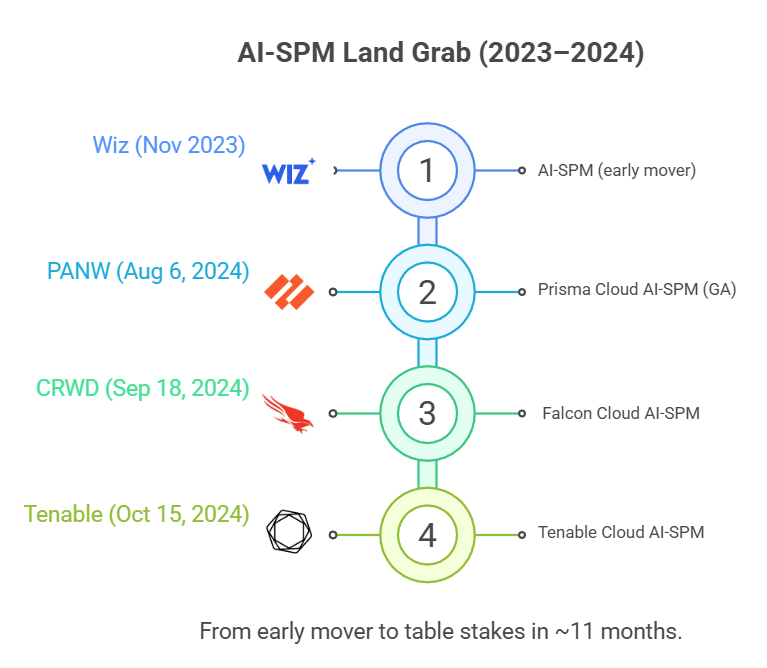
AI-SPM คือการทำให้ “เห็นภาพรวม” ว่าองค์กรกำลังใช้ AI ตรงไหนบ้าง และไล่ความเสี่ยงที่ตามมา เช่นการเจอ shadow AI (การใช้งานที่หลุดจากระบบกำกับดูแลขององค์กร), การตั้งค่าที่ผิดพลาด และความเสี่ยงจากการเชื่อมต่อหรือการให้สิทธิ์ที่กว้างเกินไป แนวคิดนี้ใกล้กับ CSPM (Cloud Security Posture Management ที่เน้นความเสี่ยงจากการตั้งค่าคลาวด์) แต่ย้ายโฟกัสมาอยู่ที่ระบบและทรัพยากรด้าน AI โดยเฉพาะ
ฝั่งผู้เล่น Wiz เปิดตัว AI-SPM ตั้งแต่ 16 พฤศจิกายน 2023 และหลังจากนั้นเริ่มเห็นค่ายใหญ่ทยอยตามมา เช่น Prisma Cloud ของ Palo Alto Networks ที่ประกาศ AI-SPM “GA” (เปิดให้ใช้งานทั่วไป) เมื่อ 6 สิงหาคม 2024 รวมถึง CrowdStrike (18 กันยายน 2024) และ Tenable (15 ตุลาคม 2024)
Mini-timeline: Wiz (Nov 2023) → Prisma Cloud GA (Aug 2024) → CrowdStrike (Sep 2024) → Tenable (Oct 2024)
สัญญาณปี 2025: แนวโน้มเริ่มชัดว่า AI-SPM ไม่ได้หยุดแค่การสแกนการตั้งค่า แต่ถูกต่อยอดไปสู่การคุมความเสี่ยงตอนใช้งานจริง โดยเฉพาะเมื่อองค์กรเริ่มใช้ AI agents มากขึ้น
มุมที่น่าคิดคือ เมื่อหลายแพลตฟอร์มใหญ่เติมความสามารถลักษณะนี้เข้าไปใน CNAPP (แพลตฟอร์มความปลอดภัยคลาวด์แบบครบชุด) มากขึ้น AI-SPM มีโอกาสถูกมองเป็น “ฟีเจอร์ที่ต้องมี” มากกว่าจะเป็นผลิตภัณฑ์เดี่ยว ซึ่งดีสำหรับผู้ซื้อที่ได้ของเพิ่มในแพ็กเกจเดิม แต่กดดันบริษัทที่พยายามขายเฉพาะ AI-SPM อย่างเดียวให้ยืนระยะได้
GA คืออะไร
GA (Generally Available) หมายถึงฟีเจอร์เปิดให้ลูกค้าใช้งานทั่วไปแล้ว ไม่ใช่ช่วงทดลอง (preview/beta)
7) Agent Identity and Access: ตลาดที่ยังเปิดกว้าง
เมื่อ AI agent เริ่มทำงานแทนคนในงานที่ “ไปแตะระบบจริง” เช่น จองตั๋ว ส่งอีเมล อนุมัติคำขอ หรือดึงข้อมูลจากฐานข้อมูล คำถามด้านความปลอดภัยจะเปลี่ยนจาก “มันตอบถูกไหม” ไปเป็น “มันมีสิทธิ์ทำสิ่งนั้นหรือเปล่า” และ “ถ้าเกิดความเสียหาย เราไล่ที่มาที่ไปได้ไหม”
ในทางปฏิบัติ “agent identity” มักหมายถึงการตอบ 3 เรื่องให้ชัด
- agent ตัวนี้คือใคร (ตัวตน, แหล่งที่มา, credential)
- agent ทำอะไรได้บ้าง (authorization, scope, policy)
- ทำไปแล้วตรวจสอบย้อนหลังได้ไหม (audit trail, attribution)
ภาพตลาดตอนนี้ยังไม่เหมือน IAM ยุคเดิมที่มีเจ้าตลาดชัด ๆ ผู้เล่นเลยแตกเป็นสองแรงหลัก
- กลุ่ม IAM/PAM เดิม (ระบบจัดการตัวตนและสิทธิ์ รวมถึงการคุมสิทธิ์พิเศษระดับแอดมิน) เช่น Okta, Ping Identity, CyberArk มีโอกาสต่อยอดของเดิมมารองรับ “ตัวตนที่ไม่ใช่คน” อย่าง bot หรือ AI agent และการมอบสิทธิ์ให้ทำงานแทนแบบจำกัดขอบเขตและตรวจสอบย้อนหลังได้
กล่องคำอธิบายศัพท์IAM (Identity and Access Management): ระบบจัดการ “ตัวตนและสิทธิ์” ว่าใครคือใคร และเข้าถึงอะไรได้บ้างPAM (Privileged Access Management): ระบบคุม “สิทธิ์พิเศษระดับแอดมิน” ที่ทำสิ่งสำคัญ/เสี่ยงได้มากNon-human identity: ตัวตนที่ไม่ใช่มนุษย์ เช่น service account, bot, workload รวมถึง AI agentDelegated access: การมอบสิทธิ์ให้ทำงานแทนแบบมีขอบเขต เช่น จำกัดงาน/เวลา/ข้อมูล และมีการอนุมัติ
- กลุ่มในฝั่ง “ชุดเครื่องมือสร้างและรัน agent” (agent stack) และ “การกำหนดสิทธิ์ด้วยโค้ด” (policy-as-code) ที่เริ่มต่อยอดเรื่องสิทธิ์ของ agent และ workflow การอนุมัติ เช่น Strata Identity (identity orchestration) และ Permit.io (authorization-as-code) รวมถึง ecosystem ของ LangChain ที่ทำให้แนวคิด “agent + tools” ถูกใช้งานจริงเร็วขึ้น
กล่องคำอธิบายศัพท์Agent stack: ชุดเครื่องมือสำหรับสร้าง/รัน/เชื่อม agent เข้ากับเครื่องมือและระบบงานPolicy-as-code: เขียนกติกาสิทธิ์และเงื่อนไขการอนุมัติเป็นโค้ด เพื่อใช้ซ้ำและตรวจสอบได้Identity orchestration: การ “จัดระเบียบและเชื่อม” ระบบตัวตนหลายแหล่งให้ทำงานร่วมกัน (เช่น HR, IAM, app ต่าง ๆ)Authorization-as-code: กำหนด “ทำได้/ทำไม่ได้” เป็นโค้ด (permissions, scopes) แทนการตั้งค่ามือในแต่ละระบบ
ตัวเร่งที่ทำให้หมวดนี้สำคัญขึ้นคือ Model Context Protocol (MCP) ของ Anthropic ซึ่งเป็นมาตรฐานกลางสำหรับการ “ต่อ agent เข้ากับ tools/ระบบงาน” ให้คุยกันรู้เรื่องในรูปแบบเดียวกัน MCP เปิดตัว 25 พ.ย. 2024 และถูกส่งต่อให้พัฒนาต่อในฐานะมาตรฐานภายใต้ Agentic AI Foundation (AAIF) ของ Linux Foundation เมื่อ 9 ธ.ค. 2025
Anthropic ระบุว่า ecosystem ของ MCP มีมากกว่า 10,000 MCP servers และมียอดดาวน์โหลด SDK (แพ็กเกจสำหรับนักพัฒนา) รวมระดับ 97M+ ต่อเดือน
ผลเชิงโครงสร้างคือ เมื่อการต่อ agent เข้ากับ tools ทำได้ง่ายและแพร่หลายขึ้น agent จะไปแตะระบบจริงมากขึ้นเรื่อย ๆ ทำให้เรื่อง “สิทธิ์ที่ทำได้”, “ขอบเขตที่อนุญาต”, และ “การตรวจสอบย้อนหลังว่าใครทำอะไรด้วยโมเดลไหน” ถูกยกระดับจาก nice-to-have กลายเป็น requirement
กล่องคำอธิบายศัพท์MCP: มาตรฐานกลางสำหรับเชื่อม agent เข้ากับ tools/ระบบงานAAIF: โครงการภายใต้ Linux Foundation ที่ดูแลการพัฒนา MCP ในฐานะมาตรฐานSDK: ชุดเครื่องมือ/แพ็กเกจสำหรับนักพัฒนาในการนำมาตรฐานไปใช้MCP server: ตัวเชื่อม (connector) ที่ให้ agent เรียกใช้ tool ได้ ไม่ใช่เครื่องเซิร์ฟเวอร์ทางกายภาพ
ถ้า agentic AI ขึ้น production ในองค์กรใหญ่จริง ๆ “สิทธิ์ของ agent” จะกลายเป็นเรื่องระดับเดียวกับระบบจัดการตัวตนและสิทธิ์ (IAM/PAM) ที่องค์กรใช้อยู่แล้ว แต่ถ้ายังอยู่แค่ pilot/PoC ตลาดจะโตช้ากว่าที่คาด และการซื้อมีแนวโน้มจะเกิดแบบค่อย ๆ เพิ่มเป็นฟีเจอร์ในแพลตฟอร์มเดิม มากกว่าซื้อผลิตภัณฑ์ใหม่ทั้งก้อน
8) AI Governance & GRC: ชนะด้วยหลักฐาน ไม่ใช่เดโม
หมวดนี้มักถูกขับเคลื่อนโดยทีม GRC, Legal, Risk, CDO หรือทีม Responsible AI มากกว่าทีม security เพียว ๆ เพราะโจทย์หลักคือ “ทำให้คุมได้จริงและตรวจสอบได้จริง” ผ่านเอกสาร หลักฐาน และ workflow การอนุมัติ ไม่ใช่แค่โชว์เดโมให้ดูสวย
เครื่องมือที่มักได้เปรียบคือเครื่องมือที่เป็น “ระบบบันทึกกลาง” ขององค์กร ทำ AI inventory ให้ครบ รู้ว่าใช้ AI อะไรอยู่ที่ไหน ใช้กับข้อมูลประเภทไหน ใครเป็นเจ้าของ ใครอนุมัติ ผ่านเกณฑ์อะไร และมี audit trail กับหลักฐานที่หยิบไปตอบ auditor หรือ regulator ได้ทันที
ตัวอย่างเช่น Credo AI มี Policy Packs ที่แปลกฎหมายและมาตรฐานให้กลายเป็น checklist และขั้นตอนที่ทีมทำงานตามได้จริง ลดภาระการตีความจากศูนย์ทุกครั้ง ส่วน ModelOp วางตัวชัดว่าเป็น AI system of record สำหรับองค์กร เพื่อให้เห็นภาพรวมและทำ governance แบบต่อเนื่องจากจุดเดียว โดยเฉพาะในองค์กรใหญ่ที่มี use case กระจายหลายทีมหลายระบบ
ความเสี่ยงของหมวดนี้คือถ้าทำได้แค่ dashboard แต่ไม่เชื่อมกับการบังคับใช้จริง สุดท้ายจะกลายเป็นของที่ “ซื้อมาแล้วไม่ถูกใช้” เพราะคนทำงานรู้สึกว่าเพิ่มงานเอกสารแต่ไม่ช่วยคุมความเสี่ยงจริง ของที่เวิร์กมักต้องผูกเข้ากับจุดที่เกิดการตัดสินใจ เช่น approval gate ก่อนขึ้น production, access control ว่าใครใช้ข้อมูลอะไรได้, หรือ quality gates ใน pipeline ที่ทำให้ระบบ “ผ่านแล้วถึงไปต่อได้” ไม่ใช่แค่บันทึกย้อนหลัง
โอกาสสำคัญของหมวดนี้คือแรงกดดันด้าน compliance โดยเฉพาะ EU AI Act ที่ทำให้หลายองค์กรต้องเตรียมระบบที่ audit-ready มากขึ้น เหตุผลไม่ใช่แค่กลัวค่าปรับ แต่เพราะเริ่มต้องตอบคำถามแบบเป็นระบบว่า “ใช้ AI อะไร กับข้อมูลอะไร ใครรับผิดชอบ และมีมาตรการคุมความเสี่ยงอะไร” โดยไทม์ไลน์เป็นแบบ phased และมีหลักไมล์สำคัญคือวันที่ 2 สิงหาคม 2026 ที่ข้อกำหนดส่วนใหญ่เริ่มมีผลกว้างขึ้น แต่รายละเอียดจริงยังขึ้นกับประเภทระบบและบทบาทขององค์กร และบางส่วนก็ยังมีข้อเสนอให้ปรับไทม์ไลน์อยู่
EU AI Act (สรุปสั้น ๆ)
EU AI Act คือกฎหมายของสหภาพยุโรปที่กำหนดกรอบกำกับดูแลการพัฒนาและการนำ AI ไปใช้ โดยเน้นระบบที่มีความเสี่ยงสูง และบังคับให้องค์กรมีเอกสาร หลักฐาน การประเมินความเสี่ยง และการกำกับดูแลที่ตรวจสอบได้
ไทม์ไลน์เป็นแบบ phased โดยมี หลักไมล์สำคัญ คือ 2 สิงหาคม 2026 ที่ข้อกำหนดส่วนสำคัญเริ่มใช้วงกว้าง แต่รายละเอียดขึ้นกับประเภทระบบและบทบาทขององค์กร
สามแรงขับที่กำหนดทิศทางตลาด
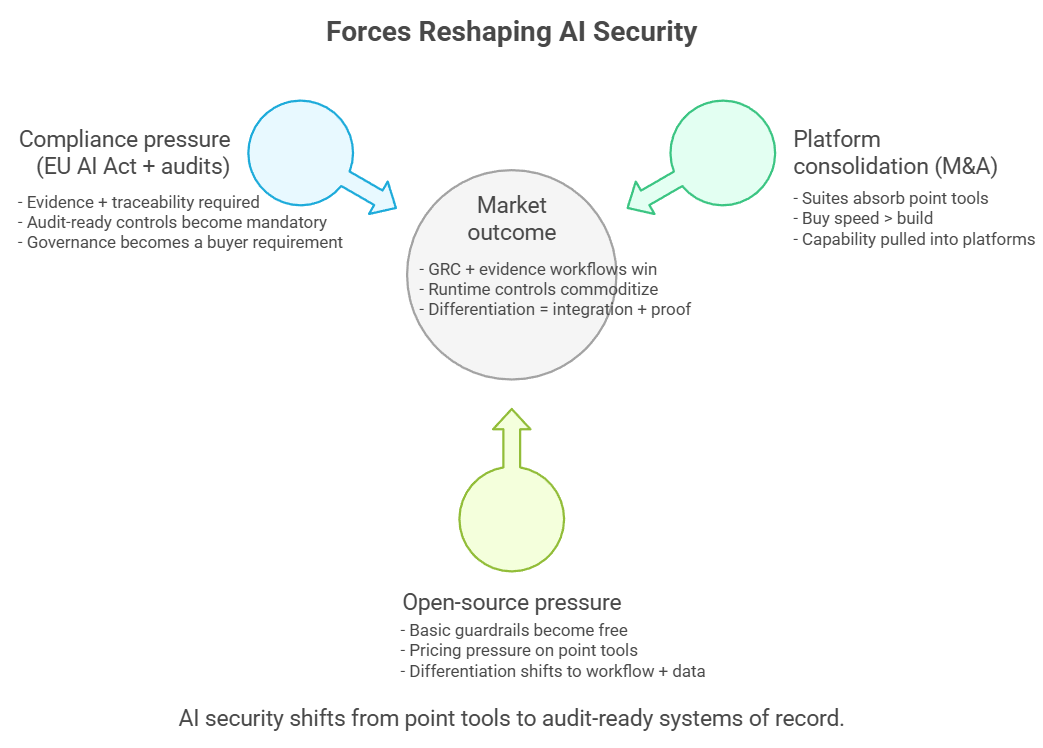
พอดูครบทั้ง 8 หมวด เราจะเริ่มเห็นภาพรวมว่าเกมตลาดไม่ได้ขับด้วยฟีเจอร์อย่างเดียว แต่มันถูกดันด้วยแรงใหญ่ 3 อย่างที่กำลังลากทั้งตลาดไปในทิศเดียวกัน
1. คลื่น M&A มาแรง ตลาดเริ่มถูกดูดเข้าหาแพลตฟอร์มใหญ่
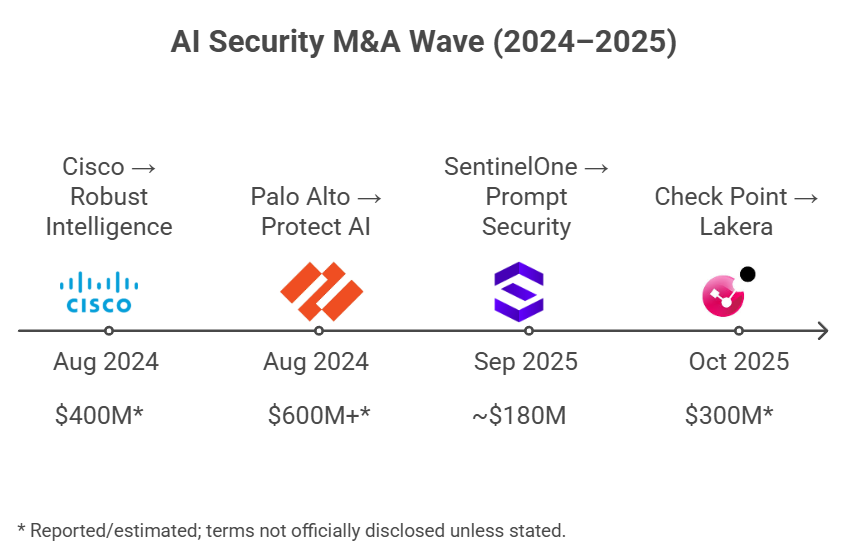
ดีลซื้อกิจการในตลาด AI Security ช่วงปี 2024–2025 ที่ “เห็นภาพชัด” มี 4 ดีลใหญ่ และในเชิงสถานะดีลถือว่า ปิดดีลแล้ว (บางดีลมีหลักฐานเป็นประกาศบริษัทโดยตรง บางดีลอ้างอิงรายงาน/แหล่งข่าวการเงิน) ดังนี้
- Cisco เข้าซื้อ Robust Intelligence
Cisco ระบุว่าปิดดีลเข้าซื้อ Robust Intelligence แล้วเมื่อเดือน ** ก.ย. 2024** โดยมีรายงานในสื่อว่ามูลค่าดีลอยู่ราว 400 ล้านดอลลาร์ และ Cisco บอกชัดว่าเทคโนโลยีของ Robust เป็นส่วนสำคัญของ Cisco AI Defense - Palo Alto Networks เข้าซื้อ Protect AI
Palo Alto Networks ระบุว่าปิดดีลแล้ววันที่ 22 ก.ค. 2025 โดยมูลค่าดีลมีรายงานอยู่แถวระดับ 600 ล้านดอลลาร์ขึ้นไป และบริษัทสื่อสารชัดว่าทีมและเทคโนโลยีของ Protect AI จะถูกนำไปต่อยอดเป็นส่วนสำคัญของ Prisma AIRS - Check Point เข้าซื้อ Lakera
Check Point ประกาศเข้าซื้อ Lakera ใน ก.ย. 2025 พร้อมระบุแผนตั้ง “Global Center of Excellence for AI Security” และมีรายงานภายนอกว่าดีลปิดแล้ววันที่ 22 ต.ค. 2025 โดยมูลค่าดีลมีรายงานราว 300 ล้านดอลลาร์ - SentinelOne เข้าซื้อ Prompt Security
SentinelOne ปิดดีล Prompt Security แล้ววันที่ 5 ก.ย. 2025 (มีเอกสาร SEC รองรับ) โดยมูลค่าดีลมีรายงานราว 180 ล้านดอลลาร์ และทิศทางคือผนวกความสามารถเข้ากับแพลตฟอร์ม Singularity เพื่อเสริมแผนด้าน GenAI security ของบริษัท
จุดร่วมที่น่าสนใจ
ผู้ซื้อทั้ง 4 รายเป็นค่าย security เดิม และของที่ซื้อเข้ามาส่วนใหญ่อยู่ใน เลเยอร์ runtime (เลเยอร์ตอนรันจริง) ของ GenAI เช่น gateway/firewall หน้าทางเข้า-ออกของโมเดล, เครื่องมือเช็กโมเดลก่อนนำมาใช้ (model supply chain), หรือความสามารถที่ช่วยคุมความเสี่ยงระหว่างระบบทำงานอยู่จริง ภาพที่สะท้อนคือค่ายใหญ่เลือก “ซื้อเพื่อให้ทันเกม” มากกว่านั่งสร้างเองทั้งหมดในระยะสั้น
คำถามที่ควรถามหลังดีลจบ
ต่อให้ปิดดีลแล้ว ข่าว PR กับของที่ลูกค้าใช้งานได้จริงมักยังไม่ใช่เรื่องเดียวกันเสมอ สิ่งที่ควรถามให้ชัดคือ “ฟีเจอร์นี้ GA แล้วหรือยัง”, “ลูกค้าใช้ได้ในสินค้าไหน ต้องเปิดโมดูลอะไร”, และ “การผนวกเข้ากับของเดิมทำได้ลึกแค่ไหน” เพราะสุดท้ายสิ่งที่มีค่าคือของที่ใช้ได้จริง ไม่ใช่สไลด์สวย ๆ ใน press release
2. Open Source กดดันราคาในแทบทุกเลเยอร์
ในแทบทุกเลเยอร์ของ AI security ตอนนี้มีของโอเพ่นซอร์สให้ทีมเอาไปใช้หรือเอาไปต่อยอดได้เลย ทำให้ “ของพื้นฐาน” ถูกกดราคาเร็วมาก ตัวอย่างที่คนพูดถึงบ่อยคือ LLM Guard ซึ่งมีรายงานว่ายอดดาวน์โหลดบน Hugging Face อยู่ระดับหลักล้านต่อเดือน แต่ต้องอ่านตัวเลขแบบมีสติ เพราะสถิติดาวน์โหลดของ Hugging Face นับจากการเรียกไฟล์บนเซิร์ฟเวอร์ (เช่น HTTP GET/HEAD) จึงเป็นตัวชี้วัดการใช้งานแบบหยาบ ไม่ได้แปลว่าเป็นจำนวนผู้ใช้จริงแบบหนึ่งต่อหนึ่ง
นอกจากนั้นยังมีโปรเจกต์โอเพ่นซอร์สที่ทีม dev รู้จักกันดี เช่น NeMo Guardrails, promptfoo, garak และ Microsoft Presidio ที่ทำให้การเริ่มต้นทำ guardrails, evals, redaction หรือ testing “ทำได้ด้วยงบใกล้ศูนย์” มากขึ้นเรื่อย ๆ
ผลที่ตามมาคือ บริษัทที่จะเก็บเงินได้จริงมักต้องขายสิ่งที่โอเพ่นซอร์สให้ไม่ได้ เช่น workflow ที่เข้ากับองค์กร, policy enforcement ที่ต่อกับระบบสิทธิ์และการอนุมัติได้จริง, telemetry/logging ที่ audit ได้, ชุดข้อมูลและ evaluation ที่สะสมจากการใช้งานจริง, หรือการ deploy ที่ทำให้ทีมทำงานได้เร็วขึ้นแบบวัดผลได้
3. ตลาดเริ่มคุยด้วยภาษาเดียวในขณะที่เส้นตาย compliance เริ่มบีบเข้ามา
OWASP LLM Top 10 ถูกหยิบมาอ้างอิงบ่อยขึ้นเรื่อย ๆ จนเริ่มกลายเป็น “ภาษากลาง” เวลาคุยเรื่องความเสี่ยงของ LLM ระหว่างฝั่งผู้ซื้อกับ vendor พอคุยกันด้วยกรอบเดียวกัน โจทย์การซื้อก็เปลี่ยนจาก “เดโมดูดีไหม” ไปเป็น “อธิบายได้ไหมว่าคุมความเสี่ยงตามกรอบนี้อย่างไร และมีหลักฐานอะไร”
พอกรอบมาตรฐานเริ่มถูกใช้เป็นภาษากลางแล้ว เรื่องถัดมาที่หนีไม่พ้นคือ “เส้นตายฝั่งกฎหมาย” ซึ่งตอนนี้ชื่อที่ถูกพูดถึงมากที่สุดคือ EU AI Act แต่กฎหมายนี้ไม่ได้เริ่มพร้อมกันทั้งหมด มันทยอยมีผลเป็นช่วง ๆ โดย 2 ส.ค. 2026 เป็นเดดไลน์สำคัญที่หลายองค์กรต้องเริ่มเตรียมระบบให้ “ใช้งานได้จริงและตรวจสอบได้” ให้ทัน ขณะเดียวกันก็มีบางส่วนที่เริ่มก่อนใน 2025, บางข้อกำหนดที่ผ่อนเวลาไปถึง 2027, และบางกรณีมีช่วงเปลี่ยนผ่านยาวถึง 2030 ขึ้นกับประเภทระบบและบริบทการใช้งาน
อีกเรื่องที่ต้องเผื่อไว้คือ ตอนนี้มีแนวคิด/ร่างข้อเสนอฝั่ง European Commission ในชุดที่สื่อเรียกรวม ๆ ว่า Digital Omnibus ซึ่งมีรายงานว่าอาจกระทบไทม์ไลน์ของข้อกำหนดบางส่วน โดยเฉพาะกลุ่ม high-risk ให้ขยับออกไปได้ แต่ประเด็นนี้ยังไม่จบ ต้องรอดูว่ากระบวนการเจรจาและอนุมัติจะไปลงตรงไหน
สรุปคือ หลายองค์กรควรมองว่า 2026 เป็นเส้นตายหลักของการเตรียมความพร้อม แต่เวลาเล่าให้คนในองค์กรฟังควรเล่าแบบ “ทยอยเป็นเฟส” จะตรงความจริงกว่า และช่วยกันความเข้าใจผิดว่า “ต้อง comply ทุกอย่างในวันเดียว”
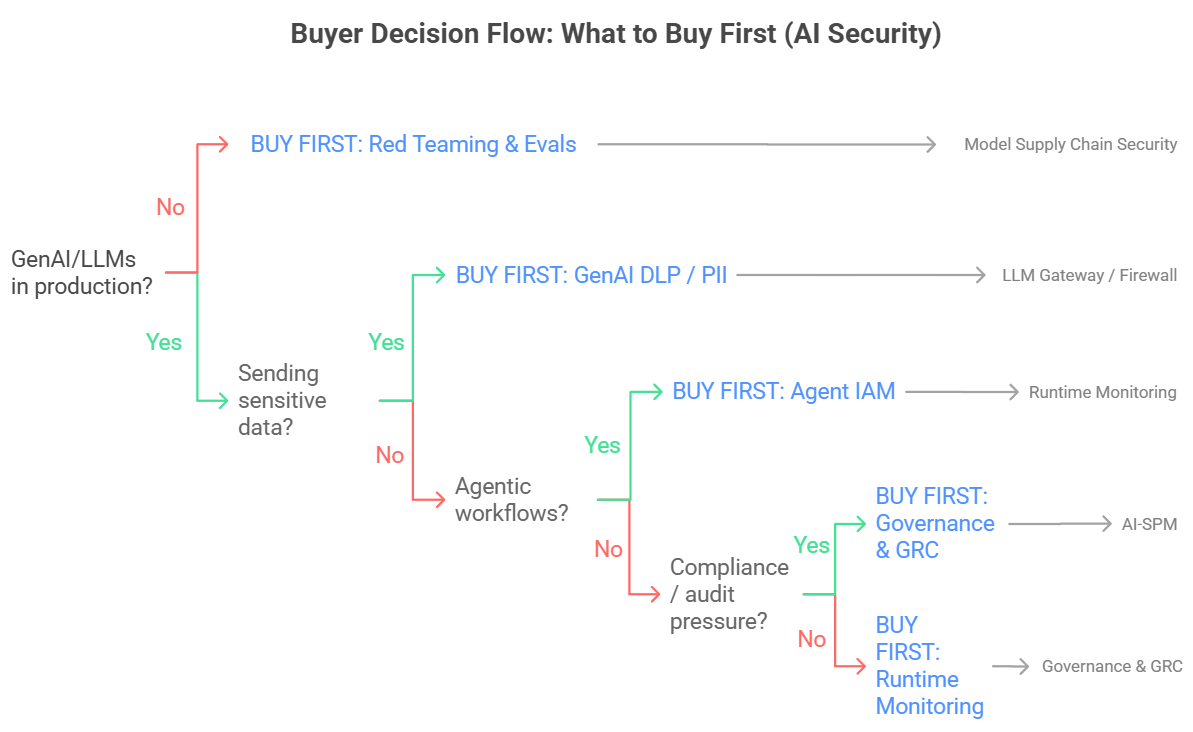
สองเรื่องที่ผู้ซื้อจะเริ่มถามหนักขึ้นในปี 2026
นอกจาก 8 หมวดและ 3 แรงขับแล้ว ยังมีอีก 2 เรื่องที่ปี 2026 นี้น่าจะได้ยินบ่อยขึ้น เพราะมันกระทบทั้งงบและรูปแบบการติดตั้งโดยตรง
1) ต้นทุนของการประเมินผลและการทดสอบ (Evals และ Red Teaming) จะกลายเป็น “บิลจริง” ที่เลี่ยงไม่ได้
พอองค์กรเริ่มทำ AI Red Teaming และ Evals แบบจริงจังในระดับองค์กร คำถามจะไม่ใช่แค่ว่า “เทสต์ได้ไหม” แต่เป็น “เทสต์แล้วค่าใช้จ่ายขึ้นเท่าไหร่” เพราะการทดสอบจำนวนมากแปลตรง ๆ เป็น inference cost ทั้งจากการรันหลายรอบ การยิงหลายโมเดล หลายเวอร์ชัน หลายชุดข้อมูล และการทำ regression ซ้ำหลังแก้ไข
สิ่งที่ผู้ซื้อจะเริ่มถามหนักขึ้นคือเรื่อง “ความคุ้ม” และ “การคุมงบ” เช่น
- ทำอย่างไรให้เทสต์ได้ลึกพอโดยไม่ทำให้ค่า API หรือค่า GPU พุ่งแบบควบคุมไม่ได้
- ทำอย่างไรให้เลือกเทสต์เฉพาะจุดเสี่ยงจริง แทนการยิงทุกเคสเท่า ๆ กัน
- ทำอย่างไรให้ผลเทสต์ผูกกับการปล่อยของได้จริง แบบไม่ผ่านก็ไม่ปล่อย โดยไม่ทำให้ pipeline ช้าเกินรับไหว
ตรงนี้จะเป็นจุดต่างที่ทำให้บริการหรือแพลตฟอร์ม “ดูโตเป็นผู้ใหญ่” กว่าคู่แข่ง เพราะมันไม่ได้ขายแค่ความปลอดภัย แต่ขาย “ความปลอดภัยที่คุมต้นทุนได้” ด้วย
สรุปสั้น ๆ
ปี 2026 Evals กับ Red Teaming จะกลายเป็นงานประจำ ต้องทำเป็นรอบและคุมงบ ไม่ใช่ทำตอนเกิดเหตุแล้วค่อยไล่แก้
2) กระแส Sovereign AI ที่องค์กรอยาก “คุมไว้ในองค์กร” และการติดตั้งแบบ on-prem หรือแบบแยกเครือข่าย (air-gapped) จะดันโจทย์ “ข้อมูลต้องไม่ออกนอกองค์กร” ให้ดังขึ้น
ประเด็นนี้จะชัดเป็นพิเศษในองค์กรที่มีข้อกำกับและข้อมูลอ่อนไหว เช่น หน่วยงานรัฐ สถาบันการเงิน อุตสาหกรรมที่มีข้อมูลละเอียดอ่อน หรือองค์กรที่เริ่มขยับไปใช้โมเดลภายในมากขึ้น
พอรูปแบบการใช้งานเอนมาทาง local LLM และ on-prem คำถามของผู้ซื้อจะเริ่มเป็นชุดเดิม ๆ คือ
- เครื่องมือ security ยังทำงานได้ไหม ถ้า ห้ามส่งข้อมูลออกไปตรวจบนคลาวด์ของผู้ให้บริการ (vendor)
- รองรับการทำงานแบบ แยกเครือข่าย ได้ไหม และ เก็บ log กับหลักฐาน ไว้ในระบบองค์กรได้ครบหรือเปล่า
- ถ้าเครื่องปลายทางไม่ได้ต่ออินเทอร์เน็ตตลอดเวลา จะ อัปเดตกติกาและ threat intel อย่างไรให้ทัน และทำได้แบบควบคุมการเปลี่ยนแปลงได้ไหม
ผลคือ ผู้ขายที่ออกแบบให้ติดตั้งได้หลายแบบ และทำงานได้จริงในสภาพแวดล้อมที่ “ข้อมูลต้องอยู่ในองค์กร” จะได้เปรียบมากขึ้น โดยเฉพาะดีลองค์กร
กล่องคำอธิบายศัพท์Sovereign AI: แนวคิดที่องค์กรหรือประเทศอยากคุมโมเดล ข้อมูล และโครงสร้างพื้นฐานเองให้มากขึ้นOn-prem: ติดตั้งและรันในดาต้าเซ็นเตอร์หรือระบบขององค์กรAir-gapped: แยกเครือข่าย ไม่เชื่อมอินเทอร์เน็ต หรือจำกัดการเชื่อมต่ออย่างเข้ม
สองเรื่องนี้จะเป็นตัวเร่งให้ตลาด “แยกชั้น” ชัดขึ้นว่าใครขายของที่เดโมแล้วดูดี กับใครขายของที่ลงระบบจริงได้ เพราะของที่ลงระบบจริงต้องตอบได้ทั้งเรื่องงบ และข้อจำกัดด้านการติดตั้งในสภาพแวดล้อมที่เข้มมาก
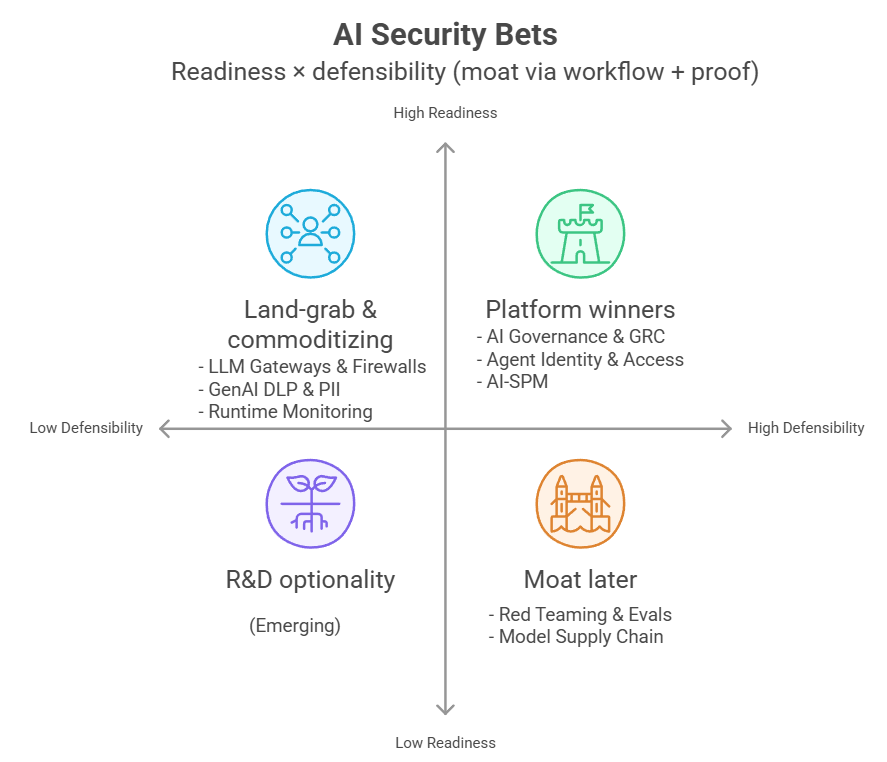
มุมมองแบบนักลงทุน: 4 สมมติฐานที่ใช้วางเดิมพัน
ข้อ 1: Model Supply Chain คือ “software supply chain” ฉบับยุค AI
พูดง่าย ๆ คือความเสี่ยงแบบซัพพลายเชนที่เราเคยเจอในโลกซอฟต์แวร์ กำลังย้ายมาอยู่ที่ “ไฟล์โมเดล” และอาร์ติแฟกต์รอบ ๆ โมเดล เช่น weights, tokenizer, config, notebook, และ pipeline artifacts
ทำไมน่าเดิมพัน
หมวดนี้น่าสนใจในมุมลงทุนเพราะ “คนทำจริงยังไม่เยอะ แต่โจทย์ยาก” ความยากไม่ได้อยู่แค่สแกนไวรัสแบบไฟล์ทั่วไป แต่ต้องรับมือความเสี่ยงเฉพาะทาง เช่น
- โค้ดไม่ปลอดภัยที่มากับการ deserialize หรือการโหลดอาร์ติแฟกต์บางชนิด
- backdoor ที่ฝังมาในโมเดล
- การปนเปื้อนในซัพพลายเชนของโมเดล (โหลดจากแหล่งภายนอกหรือผ่านหลายมือ)
อีกด้านหนึ่ง กฎระเบียบก็เริ่มกดดันให้ “ทำเอกสารและทำให้ตรวจสอบย้อนหลังได้” โดยเฉพาะกรณีที่เข้าข่าย high-risk ภายใต้ EU AI Act จึงทำให้หมวดนี้มีแรงส่งจากฝั่ง compliance ด้วย
และถ้าในอนาคตเกิดเหตุการณ์ใหญ่ที่เป็น supply chain compromise ในระดับกระทบวงกว้าง ตลาดมีโอกาสถูกเร่งให้ adopt เร็วมาก คล้ายกับช่วงที่องค์กรเริ่มทำ software supply chain security แบบจริงจัง
ข้อควรระวัง
ถ้าองค์กรส่วนใหญ่ใช้โมเดลผ่าน API มากกว่าดาวน์โหลดไฟล์โมเดลมาใช้งานเอง พื้นที่เสี่ยงฝั่ง “ไฟล์โมเดล” อาจเล็กกว่าที่คิด อีกทั้งแพลตฟอร์มอย่าง Hugging Face ก็เพิ่มการสแกนบน Hub ต่อเนื่อง ทำให้บาง use case อาจ “พอแล้ว” โดยไม่ต้องซื้อเครื่องมือเพิ่ม
แต่ไม่ได้แปลว่าหมวดนี้จะหายไป เพราะองค์กรยังต้องดูของที่อยู่นอก Hub ด้วย เช่น private models, internal registry และการคุม policy ใน pipeline ของตัวเอง
ข้อ 2: Agent Identity อาจกลายเป็น “ระบบกลาง” ที่คุมสิทธิ์ของเอเจนต์ทั้งองค์กร (control plane)
ทำไมน่าเดิมพัน
เวลารูปแบบการสร้างและใช้งานระบบเปลี่ยน เรามักเห็นว่า “เรื่องสิทธิ์กับตัวตน” ต้องปรับตามไปด้วย เพราะสุดท้ายคำถามจะกลับมาที่ประโยคเดิมเสมอว่า “ใครทำอะไรได้แค่ไหน” พอองค์กรเริ่มใช้เอเจนต์ช่วยทำงานแทนคนมากขึ้น คำถามนี้จะถูกยกระดับเป็นเรื่องที่หนีไม่พ้น และไม่ใช่แค่เรื่องล็อกอินของมนุษย์แล้ว แต่รวมถึงสิทธิ์แบบ “มอบหมายต่อกันเป็นทอด ๆ” เช่น คนมอบหมายให้เอเจนต์ เอเจนต์ส่งต่อให้เอเจนต์ย่อย แล้วไปเรียกใช้ tool หรือระบบงานจริง
อีกตัวเร่งคือ MCP (Model Context Protocol) ที่ Anthropic ปล่อยเป็นสเปกแบบเปิดตั้งแต่ปลายปี 2024 และต่อมาถูกย้ายไปพัฒนาต่อภายใต้โครงการ AAIF ของ Linux Foundation ทำให้การ “ต่อเอเจนต์เข้ากับ tool หรือระบบงาน” เริ่มมีรูปแบบที่คนใช้ร่วมกันมากขึ้น พอการเชื่อมต่อทำได้ง่ายขึ้น เอเจนต์ก็ถูกเอาไปใช้งานกับระบบจริงบ่อยขึ้นตามไปด้วย แล้วประเด็นเรื่องสิทธิ์ ขอบเขตการทำงาน และการไล่ตรวจย้อนหลังจึงถูกยกระดับจาก nice-to-have ไปเป็นของที่ต้องมีมากขึ้น
ข้อควรระวัง
- กลุ่มระบบจัดการตัวตนและสิทธิ์ (IAM) เดิมอย่าง Okta หรือ Ping Identity มีโอกาส “ขยายของเดิม” มารองรับเอเจนต์ได้เร็ว พอสู้ด้วยแพ็กเกจเดิมและช่องทางขายเดิม สตาร์ทอัพที่ขายเฉพาะ agent identity จะโดนกดทั้งเรื่องราคาและการเข้าถึงลูกค้า
- ถ้าอีก 2–3 ปีข้างหน้า เอเจนต์ยังไม่ได้ถูกเอาไปใช้ในงาน production แบบแพร่หลาย ตลาดอาจโตช้ากว่าที่หวัง และการซื้ออาจเกิดแบบ “เติมเพิ่มในของที่มีอยู่แล้ว” มากกว่าการตัดสินใจซื้อผลิตภัณฑ์ใหม่แยกเป็นก้อน
ข้อ 3: คลื่น compliance จาก EU AI Act มีแนวโน้มดันตลาดสาย GRC
ทำไมน่าเดิมพัน
EU AI Act เป็นกฎหมายที่ทยอยเริ่มมีผลเป็นช่วง ๆ และ 2 ส.ค. 2026 เป็นวันที่สำคัญ เพราะข้อกำหนดหลายส่วนเริ่มใช้กว้างขึ้น ทำให้องค์กรที่อยู่ในข่ายต้องเตรียมเอกสาร กระบวนการกำกับดูแล และหลักฐานให้ “ตรวจสอบย้อนหลังได้” มากขึ้น ไม่ใช่แค่ทำให้ผ่านเดโมหรือทำตามความรู้สึก
พอเกมกลายเป็น “ต้องตอบได้ว่า ใช้ AI อะไร อยู่ตรงไหน ใครอนุมัติ ใครรับผิดชอบ และมีหลักฐานประกอบ” เครื่องมือแนว GRC จึงได้อานิสงส์ เพราะมันถนัดเรื่อง workflow การอนุมัติ บันทึกการตัดสินใจ และ audit trail อยู่แล้ว
ข้อควรระวัง
แรงซื้อจะไม่มาเท่ากันทุกอุตสาหกรรมและทุกประเทศ และประวัติศาสตร์อย่าง GDPR ก็สอนว่า “ช่วงแรก” การตีความและความเข้มของการกำกับดูแลอาจไม่สม่ำเสมอ ทำให้องค์กรบางกลุ่มชะลอการลงทุนหรือเลือกทำแบบขั้นต่ำก่อน
อีกด้านหนึ่ง เครื่องมือสาย GRC ที่องค์กรใช้อยู่แล้วก็อาจต่อยอดเพิ่มโมดูล AI governance ได้ ทำให้ผู้เล่นหน้าใหม่ต้องชนะด้วย “ทำให้ใช้งานได้จริงในงานประจำวัน” ไม่ใช่ชนะด้วยหน้าจอสวยอย่างเดียว
กล่องคำอธิบายศัพท์GRC: Governance, Risk, Compliance ระบบงานสาย “กำกับดูแล-ความเสี่ยง-การปฏิบัติตามกฎ” ขององค์กรGDPR: กฎหมายคุ้มครองข้อมูลส่วนบุคคลของสหภาพยุโรป (เริ่มใช้ปี 2018) มักถูกยกเป็นตัวอย่างเรื่อง “การกำกับดูแลช่วงแรกอาจไม่สม่ำเสมอ”
ข้อ 4 ผู้เชี่ยวชาญด้าน indirect prompt injection มีข้อได้เปรียบเชิงเทคนิคที่ลอกยาก
ทำไมน่าเดิมพัน
โซลูชันในหมวด LLM firewall/gateway จำนวนมากมักเริ่มจากการกัน “คำสั่งอันตรายที่ผู้ใช้พิมพ์ตรง ๆ” เพราะตรวจได้ง่ายและวัดผลได้ชัด แต่ indirect prompt injection เป็นโจทย์คนละแบบ คือคำสั่งถูกซ่อนไว้ใน “ข้อมูลที่โมเดลไปอ่าน” เช่นเอกสารที่แนบมา ข้อมูลจาก RAG หรือผลลัพธ์จากเครื่องมือ (tool output) ทำให้ระบบสับสนระหว่าง “ข้อมูล” กับ “คำสั่ง” ได้ง่ายขึ้น
พอองค์กรใช้ RAG และ agent ที่เรียก tools มากขึ้น เลเยอร์ของข้อมูลภายนอกที่ไหลเข้ามาในบริบทของโมเดลก็หนาขึ้นตาม และพื้นที่โจมตีแบบนี้ก็ขยายตัวไปด้วย
ใครที่น่าจับตา
ผู้เล่นบางรายวางตำแหน่งชัดว่าโฟกัสความเสี่ยงสายนี้ เช่น PromptArmor ที่สื่อสารเรื่อง indirect prompt injection และ threat intelligence เป็นธีมหลัก หรือ Adversa AI ที่ทำคอนเทนต์/บริการเกี่ยวกับ prompt injection อย่างต่อเนื่อง
ข้อควรระวัง
ถ้า Anthropic หรือ OpenAI ทำให้การแยก “ลำดับความสำคัญของคำสั่ง” แข็งแรงขึ้นในระดับโมเดล (เช่นแนวคิด instruction hierarchy) ความต้องการเครื่องมือภายนอกบางส่วนอาจลดลง
ในอีกด้านหนึ่ง เราอาจยังไม่มีตัวเลขสาธารณะที่ชี้ชัดว่า indirect injection เกิดบ่อยแค่ไหนใน production จริง ทำให้บางองค์กรยังมองว่าเป็น “ความเสี่ยงที่เห็นภาพยาก” และยังไม่รีบซื้อจนกว่าจะมีเหตุการณ์หรือเคสใกล้ตัว
การตรวจจับแบบนี้ต้องเข้าใจ semantic context ลึกกว่าแค่ pattern matching ทำให้ต้องใช้โมเดลคุณภาพสูงและ dataset ที่มีตัวอย่างจริง ซึ่งพัฒนาช้าและสะสมยาก
สัญญาณที่ควรจับตา
ถ้าอยากดูว่าตลาด AI Security กำลังเคลื่อนไปทางไหน ลองจับสัญญาณ 3 แบบนี้
1) สัญญาณว่าตลาดเริ่ม “รวมแพลตฟอร์ม”
เริ่มเห็นความสามารถบางอย่าง (เช่น AI-SPM) ถูกใส่มาเป็นส่วนหนึ่งของแพลตฟอร์ม security ตัวใหญ่ ๆ มากขึ้น และหลายเจ้าพยายาม “รวมศูนย์การคุม” หลายเลเยอร์ไว้ในจุดเดียว เพื่อลดภาระการต่อเครื่องมือหลายตัวเข้าด้วยกัน
2) สัญญาณว่าตลาดเริ่ม “คุยกันด้วยกรอบเดียวกัน”
เอกสารจัดซื้อบางส่วนเริ่มอ้างอิงกรอบอย่าง OWASP LLM Top 10 ในคำถามหรือข้อกำหนด และผู้ซื้อจำนวนมากขึ้นเริ่มถามหา “หลักฐานที่ตรวจสอบย้อนหลังได้” มากกว่าดูเดโมสวย ๆ อย่างเดียว
3) สัญญาณว่าความเสี่ยงจาก AI เริ่มถูกคุยในระดับผู้บริหาร
ข่าวเหตุการณ์ด้าน AI security และความเป็นส่วนตัวเริ่มมีให้เห็นถี่ขึ้น ทำให้หลายองค์กรเริ่มมองว่า “ไม่ใช่แค่ปัญหาทีมเทคนิค” แต่เป็นความเสี่ยงระดับองค์กรที่ต้องมีคนรับผิดชอบและมีหลักฐานรองรับ ขณะเดียวกัน EU AI Act มีเพดานค่าปรับสูง จึงเป็นอีกแรงที่เร่งให้หลายองค์กรจริงจังกับ governance และระบบหลักฐานมากขึ้น
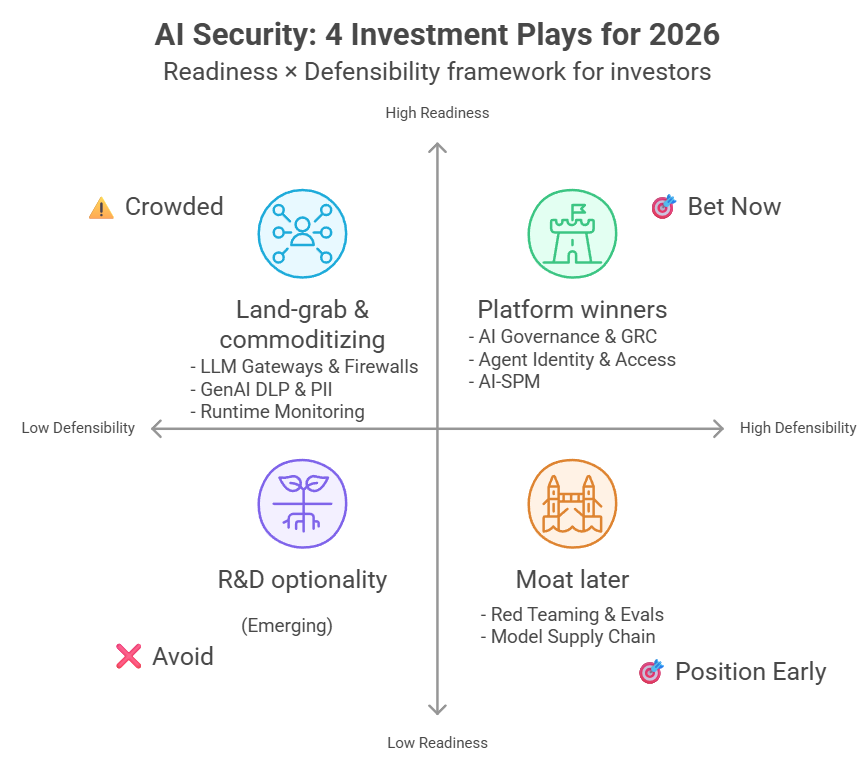
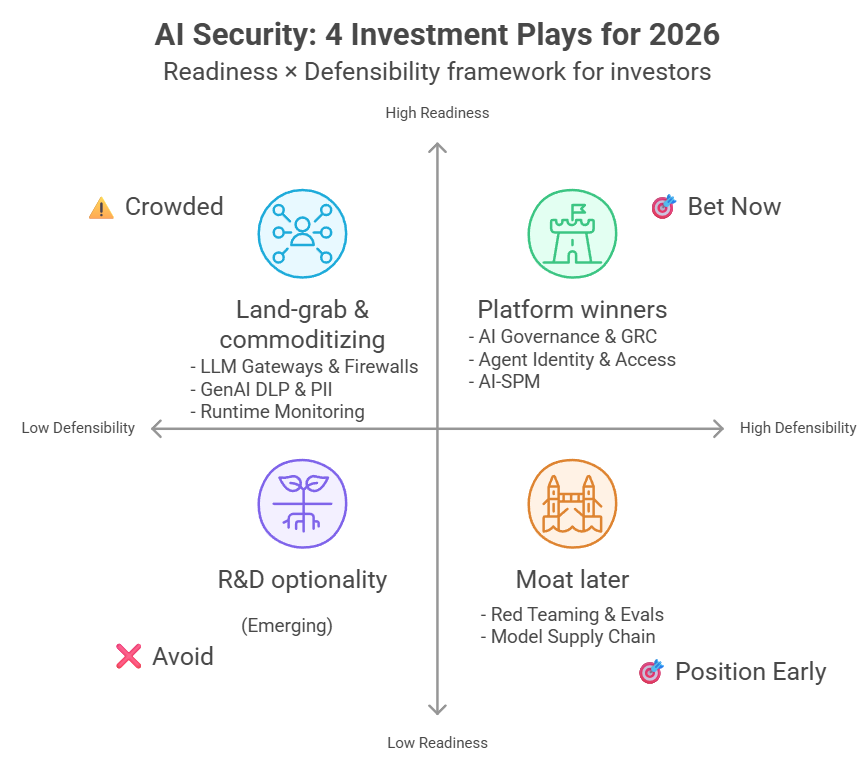
ถ้าต้องวางเงินสัปดาห์หน้า
สามหมวดที่น่าเดิมพัน
- AI Governance & GRC
เหตุผลหลักคือแรงกดดันเรื่องกฎหมายและการตรวจสอบ โดยเฉพาะ EU AI Act ที่หลายองค์กรต้องเริ่มทำระบบเอกสาร กระบวนการอนุมัติ และหลักฐานให้ “ตรวจย้อนหลังได้” มากขึ้นช่วงปี 2026 ของแบบนี้ไม่ได้ชนะด้วยเดโม แต่ชนะด้วยระบบงานที่ทำให้ทีม Legal, Risk, และผู้รับผิดชอบทำงานได้จริง - Model Supply Chain Security
หมวดนี้ยังไม่ใช่ของที่ทุกองค์กรซื้อทันที แต่โจทย์มันหนีไม่พ้นเมื่อมีการใช้โมเดลจากภายนอกมากขึ้น จุดที่ทำให้เกิดมูลค่าคือการตรวจความน่าเชื่อถือของโมเดลและ artifact ที่เกี่ยวข้อง และการผูกเข้ากับ registry หรือ pipeline ขององค์กร ถ้าวันหนึ่งมีเหตุใหญ่ที่โยงกับโมเดลใน production ตลาดจะ “เร่งตัวเอง” แบบก้าวกระโดด - AI Red Teaming แบบเน้นบริการ (services-led)
เครื่องมือทดสอบพื้นฐานเริ่มหาใช้ฟรีได้เยอะขึ้น แต่ของที่ยังมีมูลค่าคือ “ความเชี่ยวชาญและการทำซ้ำต่อเนื่อง” เช่น การออกแบบ scenario ให้ตรงธุรกิจ, การทดสอบ indirect prompt injection, เคส agent ที่เรียก tool จริง, และการช่วยทีมปิดช่องแบบวัดผลได้ รายได้จากบริการลักษณะนี้ถูกกดราคาได้ยากกว่า “ขายเครื่องมืออย่างเดียว” ในหลายองค์กร
สองหมวดที่ควรระวังเป็นพิเศษ
- LLM Firewall ที่ไม่ได้ต่างจริง
ตลาดนี้ผู้เล่นเยอะและฟีเจอร์พื้นฐานคล้ายกันมาก แถมมีทั้งโอเพ่นซอร์สและแพลตฟอร์มใหญ่ที่ใส่มาในของเดิมอยู่แล้ว ถ้าจุดขายเป็นแค่ “มี firewall” จะเหนื่อยทั้งเรื่องราคาและการแย่งช่องทางขาย - Eval harness ที่เป็นแค่เครื่องมือรันเทสต์
ถ้ามีแค่ตัวรันเทสต์ แต่ไม่มี dataset ที่สร้างเอง, ไม่มี workflow ที่เข้ากับทีม, และไม่มีการทำให้ผลทดสอบไปล็อกกับกระบวนการปล่อยงานจริง ก็เก็บเงินยาก เพราะทีมทำเองจากโอเพ่นซอร์สได้มากขึ้นเรื่อย ๆ
เช็กลิสต์ก่อนตัดสินใจ (ของจริงที่คนซื้อควรถาม)
- ของที่บอกว่าพร้อมใช้ ตอนนี้พร้อมระดับใช้งานจริงแค่ไหน มีลูกค้าใช้อยู่หรือยัง
- กัน indirect prompt injection ได้แค่ไหน มีผลทดสอบหรือเคสที่อธิบายได้ไหม
- ติดตั้งแบบไหน เป็น proxy หน้าระบบ, เป็น SDK ฝังในแอป, หรือเป็นส่วนเสริมในเครื่องมือทำงาน แต่ละแบบกระทบทีมและเวลา rollout ต่างกัน
- ต่อเข้ากับระบบองค์กรได้ไหม เช่น สิทธิ์ผู้ใช้, ขั้นตอนอนุมัติ, log/audit trail, และระบบติดตามเหตุการณ์ ไม่ใช่เครื่องมือที่ทำงานโดด ๆ
- แผนรับมือโอเพ่นซอร์สคืออะไร ถ้าของพื้นฐานมีให้ใช้ฟรี จุดที่คุณเพิ่มคุณค่าอยู่ตรงไหน
บทสรุป
ตลาด AI Security มีแนวโน้ม “ไหลไปรวมเป็นแพลตฟอร์ม” มากขึ้น โดยเฉพาะในเลเยอร์ที่อยู่ติดการใช้งานจริง เช่น เลเยอร์ด่านหน้าแบบ proxy/gateway, เลเยอร์กันข้อมูลหลุด (DLP), เลเยอร์ posture management ของ AI (AI-SPM) และเลเยอร์ governance ที่ทำเรื่องนโยบายกับหลักฐานให้ตรวจย้อนหลังได้
ภาพแบบนี้ทำให้ค่ายใหญ่ที่มีฐานลูกค้าเดิมและช่องทางขายพร้อมอยู่แล้วได้เปรียบ เพราะเขาเอาฟีเจอร์ไปใส่ในแพ็กเกจเดิมได้ง่าย ขายง่าย และดึงข้อมูลจากระบบเดิมมาใช้ต่อได้ทันที
ขณะเดียวกัน “ช่องว่าง” ก็ยังมีในบางจุดที่ตลาดยังไม่ลงตัว เช่น เรื่องสิทธิ์และตัวตนของ agent ที่ยังไม่มีรูปแบบกลางชัด ๆ, เรื่อง model supply chain ที่หลายองค์กรยังไม่ได้ซื้อจริงจังแต่มีเหตุผลจะโตเมื่อใช้โมเดลจากภายนอกมากขึ้น และโจทย์ indirect prompt injection ที่ยังเป็นจุดอับของหลายทีม เพราะมันไม่ได้มาในรูป prompt ตรง ๆ จากผู้ใช้
ถ้าจะจับทิศตลาดนี้ให้เห็นเกมจริง อย่าดูแค่ว่าใครอยู่หมวดไหน แต่ให้ดูว่าใครกำลังครอง “จุดที่งานต้องผ่านทุกวัน” เช่น จุดที่บังคับใช้นโยบายได้จริง มี log/หลักฐานครบ และเชื่อมกับกระบวนการอนุมัติขององค์กรได้ เพราะตรงนั้นมักกลายเป็นจุดที่ทำให้ลูกค้าเปลี่ยนยากและเกิดความได้เปรียบระยะยาว
ข้อมูล ณ ต้นเดือนกุมภาพันธ์ 2026
EU AI Act timeline อ้างอิง Regulation 2024/1689 Article 113
Note
รายงานฉบับนี้เป็น AI-assisted คือเราเป็นหัวหน้าโครงการ และมี AI เป็นผู้ช่วย เราเป็นคนรับผิดชอบทิศทางของรายงาน และความถูกต้องของเนื้อหาค่ะ
ใช้เวลา 2 วัน รวมการสร้างแผนภาพทั้งหลายด้วย ซึ่งถ้าเป็นสมัยก่อน การจะค้นคว้า สังเคราะห์ และวิเคราะห์ ออกมาได้ครบแบบนี้จะต้องใช้เวลาเป็นสัปดาห์แน่นอน ถือว่า AI เป็นเครื่องมือช่วยประหยัดเวลาได้ดีมาก
ขั้นตอนการทำงานมีดังนี้
- ให้ Claude และ ChatGPT หาข้อมูลเบื้องต้นมาให้
- ให้ผลัดกันตรวจสอบความถูกต้องของข้อมูล ไล่ search และ cite มาทีละอัน เราไล่ตรวจสอบจุดที่มันมีความขัดกัน หรือขัดแย้งกัน (ขั้นตอนนี้เราสั่งให้ ChatGPT มีความจ้องจับผิดเป็นพิเศษ ซึ่งแน่นอนว่ามี false positive เยอะมาก ติในสิ่งที่ไม่ผิด เป็นต้น)
- เราวางโครงให้เขียน สั่งแนวทางชัดเจน ว่าต้องการให้เนื้อหาออกมาเป็นแบบไหน เรามองแบบไหน
- ChatGPT draft 1 -> Claude ปรับแก้ เพื่อให้โครงสร้างหลักดูดีขึ้นก่อน รวมถึงการปรับระดับภาษาที่ใช้ เพราะว่าเวลาที่แก้ทีละส่วน ประโยค และการอธิบายทั้งหลาย จะได้ยึดระดับภาษาที่ปรับแล้วเป็นเกณฑ์เริ่มต้น
- เราไล่วิจารณ์เองทีละ section ปรับทิศทางของรายงาน ว่าแต่ละส่วนควรมีหน้าที่อะไร สิ่งที่ต้องการสื่อในแต่ละส่วนคืออะไร แล้วให้ ChatGPT ปรับแก้
- เราไล่วิจารณ์รายย่อหน้า สั่งการให้เพิ่มการอธิบายถ้าเห็นว่าจำเป็น ให้ ChatGPT เขียนมาให้เลือก ประมาณ 3-5 แบบ
- เราไล่วิจารณ์รายประโยค เพื่อไม่ให้ติดคำที่ดูแปร่งๆ เช่น การแปลคำมาตรงๆ ให้ ChatGPT เขียนแก้ในจุดที่มีปัญหา โดยให้สร้างตัวเลือกประมาณ 10-12 แบบ
- แปลเป็นภาษาอังกฤษ โดยการให้ ChatGPT แปลทีละส่วน เรานั่งอ่านว่าผ่านไหม
- ให้ ChatGPT สร้างข้อความที่ต้องเอามาใส่ในแผนภาพ แล้วเราเอาไปใส่ใน template จาก Napkin AI (เราเรื่องมากค่ะ ไม่ค่อยชอบแบบที่สร้างอัตโนมัติ เพราะรายละเอียดเล็กๆ ก็มีผลต่อสิ่งที่เราต้องการสื่อ)
ของแถมค่ะ: หนึ่งในไฟล์ “ข้อมูลดิบ” ที่ให้ Claude ช่วยรวบรวมเบื้องต้น
A vendor analysis mapping 30+ AI Security companies across 8 categories with detailed profiles (pricing, deployment, tech approach) plus actionable buyer workflows and investment frameworks.
แนะนำให้ตรวจสอบก่อนใช้งาน ⚠️ เพราะเป็น output ตรงจาก AI อาจมีข้อมูลคลาดเคลื่อน/ล้าสมัย หรืออ้างอิงไม่ครบ