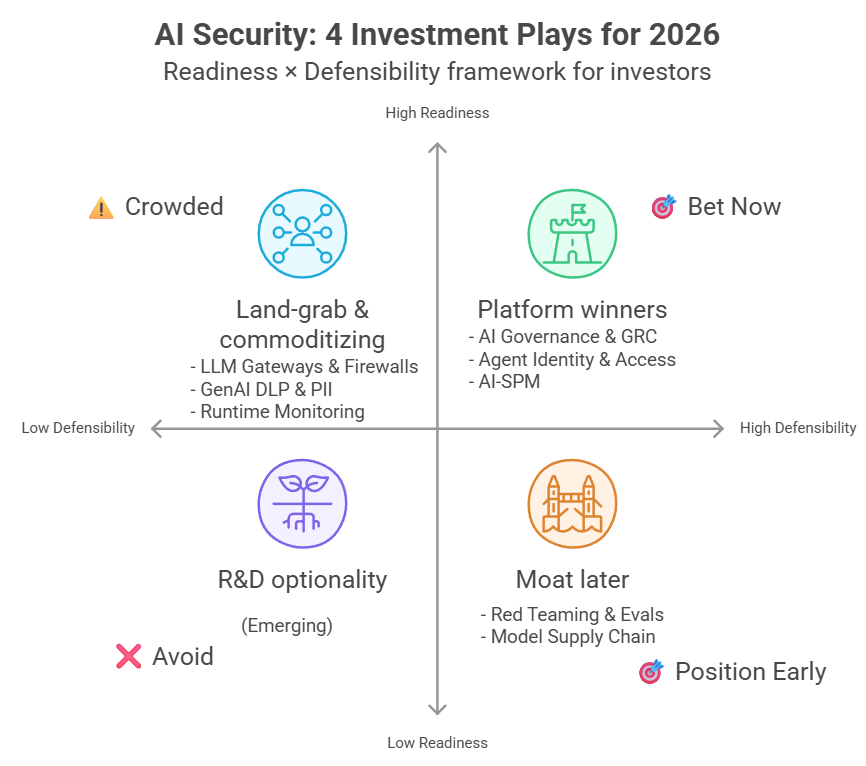
มอง LLM สไตล์ไฟแนนซ์ (3) เราบริหารความเสี่ยงกับสิ่งที่ยังไม่เกิดขึ้นได้แค่ไหนกันแน่?

ภาษาอื่น / Other language: English · ไทย
เพิ่งจะได้มาเขียนต่อจากเมื่อเดือนที่แล้วค่ะ ในสองตอนแรกเราคุยกันว่าไฟแนนซ์สร้างเครื่องมืออย่าง VaR และ Expected Shortfall ขึ้นมาไม่ใช่เพราะสูตรมันสวย แต่เพราะมนุษย์กลัว "วันที่แย่" มากกว่ากลัวค่าเฉลี่ย และเราเริ่มเห็นว่า LLM นั้นต่างจากระบบการเงินตรงที่มันอยู่ในโลกที่มี adversary มีคนที่พยายามผลักระบบจาก VaR-type failure ไปเป็น ES-type failure อยู่ตลอดเวลา
โพสต์นี้จะต่อจากตรงนั้นค่ะ โดยถามคำถามที่ใหญ่กว่าว่า เครื่องมือที่เราใช้วัดความเสี่ยงทุกชนิด รวมถึงเครื่องมือที่ดีที่สุดที่ไฟแนนซ์มี มันมีข้อจำกัดอะไรที่หลีกเลี่ยงไม่ได้?
ปี 2007 ก่อนวิกฤตจะถึงจุดพีคด้วยซ้ำ David Viniar CFO ของ Goldman Sachs ให้สัมภาษณ์กับ Financial Times เพื่ออธิบายว่าเกิดอะไรขึ้นกับกองทุนของบริษัท
เขาพูดว่า: "เรากำลังเห็นการเคลื่อนไหวระดับ 25-standard deviation หลายวันติดกัน"
และคำอธิบายแบบนี้ก็ถูกใช้เป็นภาษาความเสี่ยงที่คนในวงการคุ้นเคยกันดี
ฟังดูเป็นคำอธิบายทางวิทยาศาสตร์ แต่ถ้าเราคิดให้ดี มันคือการยอมรับสิ่งที่น่ากลัวกว่านั้นมาก
ลองนึกภาพว่า Sigma คือ "ขนาดการแกว่งตัวปกติ" ของตลาด วันที่บวกลบธรรมดา คือ 1-Sigma วันที่แปลกผิดปกติ คือ 3-Sigma วันที่ทุกคนจำได้ตลอดชีวิต คือ 5-Sigma
แล้ว 25-Sigma คืออะไร? แปลว่าโอกาสเกิดต่ำมากจนภายใต้โมเดลนั้น แทบปฏิบัติต่อมันเหมือนเป็นศูนย์ได้ ภายใต้สมมติฐานว่าโลกเป็น Gaussian ตัวเลขที่ได้ออกมาคือความน่าจะเป็นประมาณ 3×10⁻¹³⁸ ต่อวัน หรือถ้าแปลงเป็นคาบรอคาดหมาย จะยาวนานประมาณ 10¹³⁵ ปี ซึ่งนานกว่าช่วงอายุของจักรวาลอย่างเทียบกันไม่ได้เลยค่ะ
แต่ Viniar ไม่ได้บอกว่ามันเกิดขึ้นครั้งเดียว เขาบอกว่า "หลายวันติดกัน"
ฟังดูเป็นเรื่องโชคร้ายพิเศษ แต่จริงๆ มันสะท้อนโดยนัยว่า ไม้บรรทัดที่ใช้วัดโลกในวันปกติ ไม่ได้ถูกออกแบบมาเพื่อวัดโลกในวันแบบนั้น สิ่งที่ออกมาเป็น 25-sigma จึงไม่ได้แปลว่าโลกผิดปกติจนเหลือเชื่อ แต่แปลว่าไม้บรรทัดกับความเป็นจริง ณ ขณะนั้นเลิกตรงกันแล้วค่ะ
คำถามที่ควรถามจึงไม่ใช่ว่า "เราคำนวณผิดตรงไหน?"
แต่คือ "ไม้บรรทัดที่เราใช้วัดโลก... มันเหมาะกับโลกจริงไหม?"
ทุกเครื่องมือวัดความเสี่ยงที่เราเคยพูดถึง ไม่ว่าจะเป็น VaR, Expected Shortfall, Stress Testing หรือ Simulation ต่างมีสิ่งเดียวกันที่เชื่อมโยงกันอยู่ลึกๆ นั่นคือ มันทั้งหมดต้องสอบเทียบด้วยข้อมูลในอดีต แม้แต่ Scenario Analysis หรือ Stress Test ที่พยายามมองไปข้างหน้า ก็ยังต้องอาศัยความผันผวน ความสัมพันธ์ระหว่างตัวแปร และดุลพินิจของผู้เชี่ยวชาญที่ล้วนผูกติดกับสิ่งที่เคยเกิดขึ้นมาก่อน ภายใต้สมมติฐานว่าพฤติกรรมในอนาคตจะยังมีรูปแบบที่เราพอจะนึกออกค่ะ
นี่ไม่ใช่ความผิดพลาดของคนออกแบบ ไม่ใช่ความบกพร่องของสูตรคำนวณ มันคือ ข้อจำกัดเชิงโครงสร้าง ที่หลีกเลี่ยงไม่ได้
ปัญหาคือ ความเสี่ยงที่น่ากลัวที่สุด มักไม่ได้เดินตามรอยอดีต
อ่านเล่นเพิ่มเติม: Dowd, K., Cotter, J., Humphrey, C., & Woods, M. (2008). How unlucky is 25-sigma? Journal of Portfolio Management, 34(4), 76–80. บทความนี้วิเคราะห์ไว้อย่างน่าสนใจว่าทำไมเหตุการณ์ที่ "ไม่ควรเกิด" ถึงเกิดขึ้นซ้ำแล้วซ้ำเล่าในโลกการเงิน
หลัง 2008 บทเรียนสำคัญไม่ได้อยู่แค่การหาสูตรใหม่ที่แม่นกว่า แต่คือการยอมรับว่าไม่มีสูตรไหนพ้นจาก model risk
แต่สิ่งที่จดจำขึ้นใจคือ "เราต้องไม่ลืมว่าไม้บรรทัดที่เราถืออยู่อาจจะใช้งานไม่ได้เลย เมื่อโลกเปลี่ยนไปจากสมมติฐานเดิม"
และนี่คือจุดที่เชื่อมมาถึงโลก LLM โดยตรง
เรากำลังนำไม้บรรทัดของ "วันธรรมดา" ไปวัดระบบที่มีลักษณะสามอย่างพร้อมกัน:
- มันมีความไม่แน่นอนสูง (Stochastic) ผลลัพธ์ไม่ได้ซ้ำเดิมทุกครั้ง
- มันมีสิทธิ์เข้าถึงระบบและข้อมูลที่สำคัญ (Privilege) ความผิดพลาดไม่ได้อยู่แค่ในหน้าจอ
- และสิ่งที่ไม่มีในโลกการเงิน คือ มันมี ฝ่ายตรงข้ามที่คอยผลักดันระบบไปสู่จุดที่อันตรายอยู่ตลอดเวลา (Adversary)
ในตลาดหุ้นมีฝ่ายตรงข้ามอยู่จริง ไม่ว่าจะเป็นการบิดเบือนราคา การทำธุรกรรมแบบ spoofing (การวางคำสั่งซื้อขายปลอมเพื่อหลอกให้ตลาดเคลื่อนไหวตามที่ต้องการแล้วยกเลิก) หรือ front-running (การอาศัยข้อมูลคำสั่งขนาดใหญ่ที่ยังไม่เป็นสาธารณะเพื่อซื้อขายล่วงหน้า) แต่สิ่งที่ต่างกันคือระดับของการเจาะจงเป้าหมาย ใน LLM มีคนออกแบบการโจมตีที่เจาะจงพฤติกรรมและ attack surface ของระบบโดยตรง ไม่ใช่แค่หาประโยชน์จากจุดอ่อนของตลาด แต่คือการค้นหารูปแบบความล้มเหลวที่ฝังอยู่ในตัวระบบเองค่ะ
นี่คือสิ่งที่นักสถิติเรียกว่า Fat Tails คือภาวะที่เหตุการณ์สุดโต่งมีโอกาสเกิดสูงกว่าที่โมเดลปกติคาดการณ์ไว้อย่างมาก
แต่ใน LLM มันไม่ได้แค่ Fat Tails เฉยๆ เพราะนอกจากหางที่หนากว่าปกติแล้ว distribution ของระบบยังเปลี่ยนรูปไปเรื่อยๆ (non-stationary) และที่ต่างจากโลกการเงินโดยสิ้นเชิงคือมีคนจงใจค้นหาและดึงหางนั้นออกมาอย่างตั้งใจ
และที่น่ากังวลกว่านั้น ความเสี่ยงใน LLM ไม่ได้มีแค่แบบที่เกิดขึ้นเองตามสถิติ แต่ยังมีแบบที่น่ากลัวกว่า นั่นคือช่องโหว่ที่ถูกค้นพบแล้ว ใช้ซ้ำได้ และรอแค่คนเอาไปแชร์ต่อ
การทดสอบ LLM ด้วย Benchmark มาตรฐานจึงเหมือนกับการ Backtest พอร์ตหุ้นโดยใช้ข้อมูลตลาดในช่วงที่ทุกอย่างสงบ มันบอกได้แค่ว่าระบบทำงานได้ดีในวันที่ทุกอย่างปกติ แต่ยังไม่พอสำหรับระบบที่ต้องเผชิญกับผู้โจมตีที่ปรับตัวตามผลการป้องกัน และนี่เองที่ทำให้เกิดความพยายามสร้างชุดประเมินแบบ adversarial โดยเฉพาะขึ้นมาค่ะ
และเมื่อระบบใหญ่พอ ไม้บรรทัดที่วัดโลกไม่ได้ จะกลายเป็นปัญหาที่หลีกเลี่ยงไม่ได้
ในโลกของความน่าจะเป็น เหตุการณ์ที่โอกาสเกิดน้อยมาก ถ้าให้เวลานานพอหรือขยายขนาดระบบกว้างพอ สุดท้ายมันย่อมเกิดขึ้นได้เสมอ
เมื่อ LLM ถูก Deploy ในระดับที่เปิดให้คนหลายล้านคนเข้าถึง และเชื่อมต่อกับระบบงานจริงเป็นเวลานานหลายปี สามสิ่งจะเกิดขึ้นพร้อมกัน:
- เวลา ที่ยาวขึ้นทำให้ Edge Case ที่เกิดยากมาก มีโอกาสเกิดมากขึ้น ระบบที่ผ่าน Red Team มาแล้วหลายร้อยชั่วโมง ยังคงถูกเจาะได้ในเดือนที่สี่ของการใช้งานจริง เพราะทีมทดสอบมีชั่วโมงที่ระบุในสัญญา แต่โลกจริงไม่มีวันหมด scope
- คน ที่หลากหลายมากขึ้น รวมถึงคนที่ตั้งใจหาช่องโหว่ จะทดลองกับระบบในแบบที่เราไม่เคยคาดไว้ ไม่ใช่แค่ jailbreak ตรงๆ แต่เป็นการโจมตีผ่านบริบท ผ่านภาษา ผ่าน role-play หรือผ่านเอกสารที่ระบบถูกสั่งให้ไปอ่าน และที่น่าสนใจคือ แรงจูงใจของผู้ใช้จริงกับทีมทดสอบนั้นตรงข้ามกันโดยสิ้นเชิง ทีมทดสอบเมื่อทำงานได้ครบ scope แล้วหยุด ปิดงาน ส่งรีพอร์ท... แต่ผู้ใช้ที่จ่าย subscription รายเดือนอยากใช้ให้คุ้มทุกบาท ยิ่งทดลองมาก ยิ่งรู้สึกคุ้มราคาที่จ่ายไป และถ้าบังเอิญเจอช่องโหว่ระหว่างทาง นั่นก็เป็นเรื่องที่น่าสนใจจะเล่าต่อ
ความย้อนแย้งที่น่าสนใจคือ เมื่อคนจ่ายเงินเพื่อใช้งาน เขามีแนวโน้มที่จะสำรวจระบบได้ลึกกว่าทีมทดสอบที่มี scope จำกัดค่ะ และแม้จะมี bug bounty program และ red team challenge เพื่อดึงคนที่มีทักษะเข้ามาช่วยหาช่องโหว่ แต่ในความเป็นจริง คนที่มีทักษะจริงหลายคนไม่เข้าร่วมเพราะขั้นตอนยุ่งยากเกินไป เอกสารเยอะ ขอบเขตแคบ และรางวัลก็ไม่แน่นอน แต่พวกเขาก็ยังเป็นลูกค้าของระบบนั้นอยู่ดีค่ะ และถ้าบังเอิญเจอช่องโหว่ระหว่างทาง ก็แทบไม่มีแรงจูงใจพอที่จะแจ้งอย่างเป็นทางการ bug bounty จึงมักวัดได้เฉพาะกลุ่มที่ทั้งมีทักษะและยอมเข้ากระบวนการ ซึ่งอาจไม่ครอบคลุมทั้งหมดของคนที่มีความสามารถจริง
- การแพร่กระจาย ซึ่งไม่ใช่เรื่องความน่าจะเป็นอีกต่อไปค่ะ มันแพร่แบบโรคติดต่อ เมื่อมีคนหนึ่งเจอช่องโหว่ วิธีนั้นก็กลายเป็น "เชื้อ" ทันที ถูกแชร์ใน Discord ถูกโพสต์ใน Reddit ถูกทำเป็น template ต่างจากความเสี่ยงแบบสุ่มที่แต่ละเหตุการณ์เป็นอิสระต่อกัน การระบาดของ exploit มีความจำ มีการเรียนรู้ และยิ่งแพร่ยิ่งกลายพันธุ์
และที่น่ากังวลกว่านั้น ช่องโหว่เชิงพฤติกรรมของ LLM มักไม่หายไปอย่างเด็ดขาด เพราะแม้จะปิดรูปแบบหนึ่งได้ หลักการเบื้องหลังยังถูกดัดแปลงและนำกลับมาใช้ใหม่ได้เสมอ และการจะปิดช่องโหว่จุดหนึ่งโดยไม่ทำให้ความสามารถอื่นพังตามไปด้วยนั้นยากมาก ผู้พัฒนาจึงไม่อาจแก้ได้เร็วอย่างที่อยากจะแก้
สิ่งที่เคยต้องใช้ทักษะสูงจึงกลายเป็นเรื่อง copy-paste ได้ในพริบตา และยังคงใช้ได้อยู่นานกว่าที่ใครคาดไว้ค่ะ
คำถามจึงเปลี่ยนไปอย่างสิ้นเชิง จาก "เหตุการณ์เลวร้ายจะเกิดไหม?" เป็น "มันจะเกิดขึ้นเมื่อไร?"
บทเรียนจากโลกการเงินสรุปตรงๆ ได้แบบนี้:
ต่อให้เรามีเครื่องมือที่ซับซ้อนแค่ไหน ถ้าสมมติฐานพื้นฐานของไม้บรรทัดผิดตั้งแต่ต้น ตัวเลขที่ได้ออกมาก็คือ ตัวเลขที่ทำให้เรารู้สึกปลอดภัย ในขณะที่ความเสี่ยงจริงยังคงนั่งรออยู่ในมุมที่เราไม่มองถึง
และในโลก LLM ปัญหาไม่ได้อยู่แค่ที่ไม้บรรทัดที่อาจใช้ไม่ได้ มันอยู่ที่ว่าเราเอาไม้บรรทัดนั้น ผลการทดสอบ, Benchmark, Defense Rate มาตั้งเป็นเป้าหมาย แทนที่จะใช้มันเพื่อทำความเข้าใจความเสี่ยงจริงๆ
ไม้บรรทัดของวันธรรมดา ไม่เคยพร้อมสำหรับโลกที่มีคนตั้งใจทดสอบขีดจำกัดของมันอยู่ตลอดเวลา และเมื่อไม้บรรทัดนั้นกลายเป็นเป้าหมาย สิ่งที่เกิดขึ้นไม่ใช่แค่การวัดผิด แต่คือทุกฝ่ายพร้อมกัน ทั้งผู้พัฒนา ทีมประเมิน และผู้โจมตี ต่างเริ่ม optimize เข้าหามันพร้อมกัน ตัวชี้วัดที่ตั้งใจไว้เพื่อ 'มองความเสี่ยง' จึงกลายเป็นกลไกที่ 'บิดรูปความเสี่ยง' เองค่ะ นี่คือสิ่งที่เราเรียกว่า Goodhart's Law และมันจะเป็นจุดเริ่มต้นของโพสต์ถัดไปค่ะ